Auto Machine Learning, hacia la automatización de los modelos
Un modelo matemático es, en cierto modo, una simplificación de la realidad que aprovecha la información disponible para facilitar la toma de decisiones. Esta simplificación permite evaluar hipótesis sobre el comportamiento tanto de variables como de sistemas a través de su representación resumida bajo un conjunto de postulados, habitualmente basada en datos y aplicando criterios de inferencia. Tiene como principal fin explicar, analizar o predecir el comportamiento de una variable.
Auto Machine Learning
La revolución de las técnicas de modelización, junto con el incremento de la potencia de computación y la mayor accesibilidad y aumento de la capacidad de almacenamiento de datos, ha cambiado de manera radical la manera de construir modelos en los últimos años. Esta revolución ha sido un factor clave que ha estimulado no solo el uso de estas nuevas técnicas en los procesos de toma de decisiones donde clásicamente se usaban enfoques tradicionales, sino también en ámbitos donde no era tan habitual el uso de modelos. Por último, en algunos sectores, como por ejemplo en el sector financiero, el uso de modelos ha sido impulsado además por la regulación. Normas como las NIIFs 9 y 13 o Basilea II han promovido el uso de modelos internos con el objetivo de añadir sensibilidad y mejorar la sofisticación del cálculo del deterioro contable o de la determinación de los riesgos financieros.
Aunque pudiera parecer lo contrario, las técnicas de modelización más comúnmente aplicadas en el ámbito empresarial no tienen un origen reciente. En concreto, las regresiones lineales y logísticas datan del siglo XIX. No obstante, de un tiempo a esta parte se ha producido un significativo desarrollo de nuevos algoritmos, que tiene como objetivo sofisticar la forma en la que se encuentran patrones en los datos, pero también introduce nuevos retos como la mejora de las técnicas de interpretabilidad. La aplicación de estos nuevos modelos matemáticos a la computación es una disciplina científica conocida como aprendizaje automático o machine learning, ya que permite que los sistemas puedan aprender y encontrar patrones sin ser explícitamente programados para ello.
Existen múltiples definiciones del aprendizaje automático. Entre ellas, dos de las más ilustrativas son las de Samuel y Mitchell. Para Arthur Samuel, el aprendizaje automático es “el campo de estudio que da a las computadoras la habilidad de aprender sin ser programadas explícitamente”, mientras que para Tom Mitchell se define como “un programa que aprende de la experiencia E con respecto a alguna clase de tareas T y en función de una medida de rendimiento P, si este rendimiento en las tareas en T, según la medida de P, mejora con la experiencia E”. Estas dos definiciones se relacionan habitualmente con el aprendizaje no supervisado y el aprendizaje supervisado respectivamente.
Como consecuencia de todo ello, el apetito para comprender adecuadamente y extraer conclusiones de los datos se ha incrementado drásticamente. Pero, de manera paralela, la implantación de estos métodos ha requerido modificar múltiples aspectos en las organizaciones, y es, a su vez, foco de posibles riesgos derivados de errores en su desarrollo o implementación, o de su uso inadecuado.
La modelización avanzada permite mejorar los procesos comerciales y operativos, o incluso facilita la aparición de nuevos modelos de negocio. Un ejemplo puede encontrarse en el sector financiero, donde las nuevas metodologías, en el contexto de la digitalización, están modificando la propuesta de valor actual, pero también añadiendo nuevos servicios. Según una encuesta realizada por el Bank of England y la Financial Conduct Authority sobre casi 300 empresas del sector financiero y asegurador, dos tercios de los participantes utilizan machine learning en sus procesos. Las técnicas de machine learning se utilizan con frecuencia en tareas típicas de control, como la prevención del blanqueo de capitales (AML, por sus siglas en inglés), el análisis de las amenazas relacionadas con ciberseguridad o la detección de fraude, así como en los procesos de negocio, tales como la clasificación de clientes, los sistemas de recomendación o la atención a clientes a través del uso de chatbots. También son utilizadas en la gestión del riesgo de crédito, en pricing, en la ejecución de operaciones o en la suscripción de seguros.
En otros sectores se puede observar un grado de desarrollo similar. El uso de modelos de machine learning es habitual en sectores como el manufacturero, el transporte, la medicina, la justicia o los sectores de retail y gran consumo. Esto ha hecho que la inversión en empresas dedicadas a la inteligencia artificial aumentase de 1.300 millones de dólares en 2010 a 40.400 millones en 2018 a nivel global. El retorno esperado justifica esta inversión: el 63% de las empresas que han adoptado el uso de modelos de machine learning en sus unidades de negocio informan de un aumento de los ingresos, siendo de más del 6% para aproximadamente la mitad de ellas. Asimismo, el 44% de las empresas reportan un ahorro de costes, siendo superior al 10% para aproximadamente la mitad de ellas.
De los distintos cambios que se han registrado en las organizaciones para adaptarse a este nuevo paradigma, la captación y retención del talento está siendo uno de los elementos centrales. En primera instancia, se ha requerido un aumento de los equipos especialistas en machine learning. La demanda de profesionales en este ámbito ha aumentado un 728% entre 2010 y 2019 en Estados Unidos, registrándose también un cambio cualitativo en la demanda de habilidades y conocimientos de los data scientists.
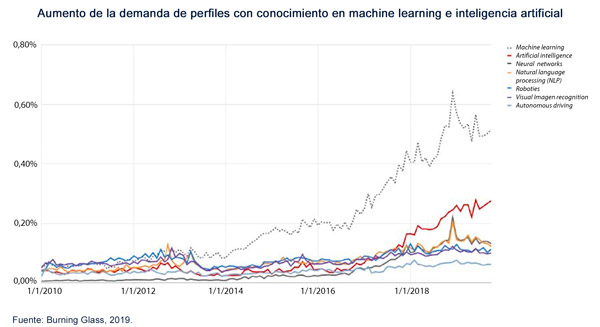
Pero esta demanda no es genérica: con la intención de explotar la cada vez mayor cantidad de datos disponibles mediante herramientas cada vez más sofisticadas, los requisitos se han vuelto más específicos (entre los que se incluye el conocimiento de diferentes lenguajes de programación, como Python, R, Scala o Ruby, capacidad para el tratamiento de bases de datos en arquitecturas big data, conocimientos en cloud computing, conocimientos matemáticos y estadísticos avanzados, encontrarse en posesión de posgrados especializados, etc.), existiendo una gran diversidad de posiciones, con requisitos muy concretos y, por tanto, difícil de cubrir. Además, el gran aumento registrado en el volumen de generación de datos por parte de las empresas hace que, incluso con una oferta estable de data scientists, la solución actual de contratación de recursos no sea escalable.
Esta inclusión de modelos de machine learning no solo hace necesario el establecimiento de equipos especialistas, sino también el uso de nuevos procedimientos de desarrollo, y la revisión de los métodos de validación, revisión y evaluación de los modelos dentro de los ámbitos de validación y auditoría, así como un importante cambio cultural en el resto de áreas para conseguir una implementación efectiva. La inclusión de estos nuevos procesos genera una reacción en cadena que afecta a todo el ciclo de vida de los modelos, destacando entre ellos la identificación y gestión del riesgo de modelo, así como su gobierno. Muchos de estos modelos requieren, adicionalmente, la aprobación de organismos supervisores, como ocurre en la industria financiera (por ejemplo, en los modelos de capital o provisiones), o en la industria farmacéutica, lo que añade retos adicionales a los ya existentes, como son la necesidad de garantizar la interpretabilidad de los modelos utilizados, así como desarrollar el resto de elementos de confianza de los modelos.
Otro aspecto destacable sobre la inversión en métodos de machine learning es que esta tiene un desarrollo desigual: la obligación de superar procesos de validación, auditoría y aprobación, según la regulación establecida, o el requisito de mantener unos estándares específicos de documentación, está generando diferencias en la implantación de modelos internos de las empresas. De acuerdo con el informe sobre big data y analytics de la EBA, las entidades financieras están adoptando programas de transformación digital o impulsando el uso de técnicas de machine learning en aspectos como la mitigación de los riesgos (incluyendo scorings automáticos, gestión de riesgo operacional o fraude) y en procesos de Know Your Customer. No obstante, “aunque la aplicación de machine learning puede suponer una oportunidad para optimizar el capital, desde la perspectiva de un marco prudencial es prematuro considerar apropiado el uso de técnicas de machine learning para determinar los requerimientos de capital”.
Existen además riesgos operacionales difíciles de detectar, como pueden ser los de carácter humano durante el proceso de implementación de un modelo o los relacionados con la seguridad del almacenamiento de datos, que deben ser gestionados convenientemente para garantizar el uso de estos sistemas en un entorno adecuado. Esto adquiere una relevancia significativa para las empresas que operan en entornos considerados de alto riesgo. Un ejemplo de ello es el marco que ha establecido la Comisión Europea en estos casos y que engloba distintos aspectos del proceso de modelización. Por último, y también debido tanto a criterios regulatorios como de gestión, los modelos deben funcionar de forma fiable y ser utilizados de forma ética, de modo que el usuario pueda confiar en ellos para su uso en los procesos de toma de decisiones. En esta línea, resulta de especial interés la propuesta de la EBA basada en siete pilares de confianza: ética, interpretabilidad, eliminación de discriminaciones, trazabilidad, protección y calidad de los datos, seguridad y protección al consumidor. Estas cuestiones se han identificado como elementos clave también desde los ámbitos universitario y empresarial.
En este contexto las tareas de desarrollo de modelos demandan dedicaciones muy desiguales: las tareas previas y complementarias al análisis requieren de una gran cantidad de tiempo y recursos dirigidas a la preparación, limpieza y tratamiento general de los datos; el 60% del tiempo de un data scientist se dedica a la limpieza de datos y a organizar la información, mientras que un 9% y un 4% se focaliza en tareas de knowledge discovery y el refinamiento de algoritmos, respectivamente. Todo ello impulsa la necesidad de cambiar la forma de abordar el desarrollo, la validación y la implementación de modelos, de forma que se aprovechen las ventajas de las nuevas técnicas, pero resolviendo las dificultades asociadas a su utilización, así como mitigando sus posibles riesgos.
Derivado de los motivos comentados anteriormente, existe una tendencia clara hacia la automatización de los procesos relacionados con la aplicación de técnicas de advanced analytics, que se ha denominado, de manera general, machine learning automatizado (AutoML o automated machine learning, indistintamente), cuyo objetivo es no solo automatizar aquellas tareas donde los procesos heurísticos son limitados y fácilmente automatizables, sino también permitir la generación de procesos de búsqueda de patrones y de algoritmos más automática, ordenada y trazable. De acuerdo con Gartner, más del 50% de las tareas data science estarán automatizadas en el año 2025.
Pero además, esta tendencia a la automatización ofrece una serie de oportunidades, como las que brinda la arquitectura de sistemas utilizados en la automatización en términos de diseño de los workflows, de inventario de modelos o de validación por componentes. Los sistemas de AutoML integran diversas herramientas para desarrollar modelos, reduciendo además el coste, el tiempo de desarrollo y los errores en la implementación de dichos sistemas.
Tanto los sistemas como los métodos de AutoML persiguen, entre otras cosas:
- Reducir el tiempo dedicado por los data scientists en el desarrollo de modelos a través de técnicas de machine learning, e incluso permitir el desarrollo de algoritmos de machine learning por parte de equipos no especializados en data science.
- Mejorar el desempeño de los modelos desarrollados, así como la trazabilidad y comparabilidad de los modelos obtenidos frente a las técnicas de búsqueda de hiperparámetros manual.
- Permitir cuestionarse los modelos desarrollados mediante otros enfoques.
- Reaprovechar la inversión realizada tanto en tiempo como en recursos para el desarrollo de códigos y mejorar y refinar los componentes incluidos en los sistemas de forma eficiente y con mayor trazabilidad.
- Simplificar la validación de los modelos y facilitar su planificación.
En este contexto, el presente documento pretende describir los principales elementos sobre los sistemas de AutoML. Para ello, se ha estructurado en tres apartados, que se corresponden a su vez con tres objetivos:
- En el primer apartado se analiza la evolución en la automatización de los procesos de machine learning, así como los motivos que subyacen en el desarrollo de sistemas de AutoML, tanto a través de la componentización, como de la automatización de los mismos.
- En el segundo bloque se aporta una visión descriptiva sobre los principales marcos de AutoML, y se explica qué enfoques se están siguiendo, tanto en el ámbito académico como en experiencias prácticas dirigidas a automatizar los procesos de modelización a través de técnicas de machine learning.
- Por último, el tecer apartado tiene como objetivo ilustrar los resultados del desarrollo de sistemas de AutoML, presentando como caso de estudio una competición organizada por Management Solutions a inicios de 2020 dirigida a los profesionales de la Firma y cuyo objetivo fue el diseño de un modelo de Automated Machine Learning.
Para más información, accede al documento completo. Documento también disponible en inglés y portugués.
Otros documentos relacionados: Machine Learning, una pieza clave en la transformación de los modelos de negocio | Data science y la transformación del sector financiero | Model Risk Management: Aspectos cuantitativos y cualitativos de la gestión del riesgo de modelo