Auto Machine Learning, rumo à automação dos modelos
Um modelo matemático é, de certa forma, uma simplificação da realidade que tira proveito das informações disponíveis para sistematizar a tomada de decisões. Essa simplificação permite que hipóteses sobre o comportamento de variáveis e sistemas sejam avaliadas através de sua representação sumária sob um conjunto de postulados, geralmente com base em dados e aplicando critérios de inferência. Seu principal objetivo é explicar, analisar ou prever o comportamento de uma variável.
Auto Machine Learning
A revolução nas técnicas de modelagem, combinada com maior poder computacional, maior acessibilidade e maior capacidade de armazenamento de dados, mudou radicalmente a forma como os modelos são construídos nos últimos anos. Essa revolução foi um fator-chave que estimulou não apenas o uso dessas novas técnicas nos processos de tomada de decisão, onde as abordagens tradicionais eram usadas, mas também em áreas onde o uso de modelos não era tão comum. Por fim, em alguns setores, como o setor financeiro, o uso de modelos também foi impulsionado pela regulamentação. Normas como IFRS 9 e 13 ou Basileia II promoveram o uso de modelos internos com o objetivo de aumentar a sensibilidade e melhorar a sofisticação do cálculo de deterioração contábil ou determinação de riscos financeiros.
Embora possa parecer o contrário, as técnicas de modelagem mais comuns aplicadas no campo de negócios não têm uma origem recente. Especificamente, as regressões lineares e logísticas datam do século XIX. No entanto, há algum tempo, há um desenvolvimento significativo de novos algoritmos, cujo objetivo é refinar a maneira como os padrões são encontrados nos dados, mas também apresenta novos desafios, como melhorar as técnicas de interpretabilidade. A aplicação desses novos modelos matemáticos à computação é uma disciplina científica conhecida como aprendizado automático ou machine learning, pois permite que os sistemas aprendam e encontrem padrões sem serem explicitamente programados para isso.
Existem várias definições de machine learning. Entre elas, as duas mais ilustrativos são os de Samuel e Mitchell. Para Arthur Samuel, o machine learning é "o campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados", enquanto para Tom Mitchell é definido como “um programa que aprende com a experiência E com relação a alguma classe de tarefas T e com base em uma medida de desempenho P, se esse desempenho nas tarefas em T, de acordo com a medida de P, melhorar com a experiência E". Essas duas definições geralmente estão relacionadas a aprendizado não supervisionado e aprendizado supervisionado, respectivamente.
Como conseqüência, o apetite para entender e tirar conclusões dos dados aumentou dramaticamente. Mas, paralelamente, a implementação desses métodos exigiu modificações em múltiplos aspectos nas organizações, e é, por sua vez, o foco de possíveis riscos decorrentes de erros em seu desenvolvimento ou implementação, ou seu uso inadequado.
A modelagem avançada melhora os processos comerciais e operacionais, ou até facilita o surgimento de novos modelos de negócios. Um exemplo pode ser encontrado no setor financeiro, onde novas metodologias, no contexto da digitalização, estão modificando a proposta de valor atual, mas também adicionando novos serviços. De acordo com uma pesquisa realizada pelo Banco da Inglaterra e pela Autoridade de Conduta Financeira de quase 300 empresas do setor financeiro e de seguros, dois terços dos participantes usam o machine learning em seus processos. As técnicas de machine learning são frequentemente usadas em tarefas de controle típicas, como prevenção à lavagem de dinheiro (AML), análise de ameaças relacionadas à ciberssegurança ou detecção de fraude, bem como em processos de negócios, como a classificação de clientes, sistemas de recomendação ou atendimento ao cliente através do uso de chatbots. Também são utilizados no gerenciamento de risco de crédito, precificação, na execução de operações ou na subscrição de seguros.
Um grau semelhante de desenvolvimento pode ser observado em outros setores. O uso de modelos de machine learning é comum em setores como manufatura, transporte, medicina, justiça ou nos setores de varejo e bens de consumo. Isso fez com que o investimento em empresas dedicadas à inteligência artificial aumentasse de US $ 1,3 bilhão em 2010 para US $ 40,4 bilhões em 2018 no mundo. O retorno esperado justifica esse investimento: 63% das empresas que adotaram o uso de modelos de machine learning em suas unidades de negócios relatam um aumento na receita, sendo mais de 6% para aproximadamente metade delas. Da mesma forma, 44% das empresas relatam economia de custos, sendo mais de 10% para aproximadamente metade delas.
Das diferentes mudanças registradas nas organizações para se adaptar a esse novo paradigma, o recrutamento e a retenção de talentos ainda são dos elementos centrais. Em um primeiro momento, foi necessário um aumento nas equipes de especialistas em machine learning. A demanda por profissionais nesse campo aumentou 728% entre 2010 e 2019 nos Estados Unidos, também registrando uma mudança qualitativa na demanda por habilidades e conhecimentos dos cientistas de dados.
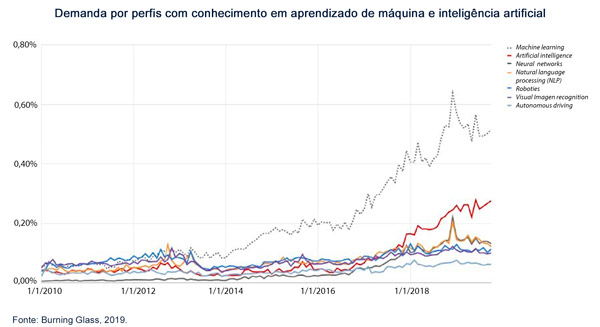
Mas essa demanda não é genérica: com a intenção de explorar a quantidade crescente de dados disponíveis por meio de ferramentas cada vez mais sofisticadas, os requisitos se tornaram mais específicos (incluindo o conhecimento de diferentes linguagens de programação, como Python , R, Scala ou Ruby, capacidade de tratamento de bancos de dados em arquiteturas de big data, conhecimento em computação em nuvem, conhecimento avançado em matemática e estatística, posse de cursos de pós-graduação especializados, etc.), com grande diversidade de posições, com requisitos muito específicos e, portanto, difíceis de atender. Além disso, o grande aumento no volume de geração de dados pelas empresas significa que, mesmo com um suprimento estável de cientistas de dados, a solução atual de recrutamento de recursos não é escalável.
Mas não é apenas necessário estabelecer equipes especializadas, mas também o uso de novos procedimentos de desenvolvimento, a revisão dos métodos de validação, revisão e avaliação dos modelos nas áreas de validação e auditoria, além de uma mudança cultural importante nas outras áreas para alcançar uma implementação eficaz. A inclusão desses novos processos gera uma reação em cadeia que afeta todo o ciclo de vida dos modelos, destacando entre eles a identificação e o gerenciamento de riscos do modelo, bem como sua governança. Muitos desses modelos exigem adicionalmente a aprovação dos órgãos de supervisão, como ocorre no setor financeiro (por exemplo, nos modelos de capital ou de provisão) ou na indústria farmacêutica, o que acrescenta desafios adicionais aos já existentes, como é necessário garantir a interpretabilidade dos modelos utilizados, bem como desenvolver os demais elementos de confiança dos modelos.
Outro aspecto notável do investimento em métodos de machine learning é que ele tem um desenvolvimento desigual: a obrigação de passar nos processos de validação, auditoria e aprovação, de acordo com a regulamentação estabelecida ou a exigência de manter padrões específicos de documentação, está gerando diferenças na implantação de modelos internos das empresas. De acordo com o relatório sobre big data e analytics da EBA, as instituições financeiras estão adotando programas de transformação digital ou promovendo o uso de técnicas de machine learning em aspectos como mitigação de riscos (incluindo pontuação automática, gerenciamento de riscos operacionais ou fraude) e nos processos de Know Your Client. No entanto, “embora a aplicação do machine learning possa representar uma oportunidade para otimizar capital, da perspectiva de uma estrutura prudencial, é prematuro considerar o uso de técnicas de machine learning apropriadas para determinar os requisitos de capital”.
Também existem riscos operacionais difíceis de detectar, como os de natureza humana durante o processo de implementação de um modelo ou os relacionados à segurança do armazenamento de dados, que devem ser convenientemente gerenciados para garantir o uso desses sistemas em um ambiente adequado. Isso adquire relevância significativa para empresas que operam em ambientes considerados de alto risco. Um exemplo disso é o framework estabelecido pela Comissão Europeia nestes casos e que engloba diferentes aspectos do processo de modelagem. Por fim, e também devido a critérios regulatórios e de gestão, os modelos devem funcionar de forma confiável e devem ser usados de forma ética, para que o usuário possa confiar neles para uso nos processos de tomada de decisão. Nesta linha, é de especial interesse a proposta da EBA baseada em sete pilares de confiança: ética, interpretabilidade, eliminação da discriminação, rastreabilidade, proteção e qualidade dos dados, segurança e proteção do consumidor. Essas questões foram identificadas como elementos-chave em universidades como também por empresas.
Nesse contexto, as tarefas de desenvolvimento de modelos exigem tempos muito desiguais: as tarefas anteriores e complementares à análise também exigem uma grande quantidade de tempo e recursos destinados à preparação, limpeza e tratamento geral dos dados; 60% do tempo de um cientista de dados é gasto limpando dados e organizando informações, enquanto 9% e 4% se concentram em tarefas de descoberta de conhecimento e refinamento de algoritmos, respectivamente. Tudo isso leva à necessidade de mudar a maneira de abordar o desenvolvimento, a validação e a implementação de modelos, para que sejam exploradas as vantagens de novas técnicas, mas resolvendo as dificuldades associadas ao seu uso, além de mitigar seus possíveis riscos.
Em decorrência das razões acima mencionadas, há uma clara tendência em direção à automação de processos relacionados à aplicação de técnicas avançadas de análise, que tem sido geralmente chamada de aprendizado automático de máquina (AutoML ou automated machine learning, de forma intercambiável), cujo objetivo não é apenas automatizar as tarefas em que os processos heurísticos são limitados e facilmente automatizáveis, mas também permitir a geração de processos e algoritmos de pesquisa de padrões mais automáticos, ordenados e rastreáveis. De acordo o Gartner, mais de 50% das tarefas de ciência de dados serão automatizadas até 2025.
Essa tendência para a automação é explicada não apenas pelas questões levantadas acima, mas também pelas oportunidades oferecidas pela arquitetura dos sistemas utilizados, em termos de design de fluxo de trabalho, inventário de modelo ou validação de componentes. Os sistemas de AutoML integram várias ferramentas para desenvolver modelos, reduzindo também custos, tempo de desenvolvimento e erros na implementação de tais sistemas.
Os sistemas e métodos de AutoML buscam, entre outras coisas:
- Reduzir o tempo gasto pelos cientistas de dados no desenvolvimento de modelos por meio de técnicas de machine learning e até mesmo permitir o desenvolvimento de algoritmos de machine learning e por equipes não especializadas em ciência de dados.
- Melhorar o desempenho dos modelos desenvolvidos, bem como a rastreabilidade e comparabilidade dos modelos obtidos com as técnicas de busca manual por hiperparâmetros.
- Permitir questionar os modelos desenvolvidos por outras abordagens.
- Reutilizar o investimento feito em tempo e recursos para desenvolvimento de códigos, melhorar e refinar os componentes incluídos nos sistemas de forma eficiente e com maior rastreabilidade.
- Simplificar a validação dos modelos e facilitar seu planejamento.
Neste contexto, este documento tem como objetivo descrever os principais elementos sobre os sistemas de AutoML. Para isso, foi estruturado em três seções, que por sua vez correspondem a três objetivos:
- No primeiro bloco, a evolução na automação dos processos de machine learning é analisada, assim como os motivos subjacentes no desenvolvimento de sistemas de AutoML.
- O segundo bloco fornece uma visão descritiva das principais estruturas do AutoML e explica quais abordagens estão sendo seguidas, tanto academicamente quanto em experiências práticas destinadas a automatizar processos de modelagem por meio de técnicas de machine learning.
- Por fim, o terceiro bloco tem como objetivo ilustrar os resultados do desenvolvimento de sistemas de AutoML, apresentando como estudo de caso um campeonato organizado pela Management Solutions no início de 2020, dirigido aos profissionais da firma e cujo objetivo foi o desenho de um modelo de Automated Machine Learning.
Para mais informações, acesse o documento completo en PDF (também disponível em Espanhol e Inglês).
Outros documentos relacionados: Machine Learning, uma peça-chave na transformação dos modelos de negócio | Data science e a transformação do setor financeiro | Model Risk Management: Aspectos quantitativos equalitativos da gestão do risco de modelo