GenAI: una aproximación a los sistemas multiagente
La Cátedra iDanae (inteligencia, datos, análisis y estrategia) en Big Data y Analytics, creada en el marco de colaboración de la Universidad Politécnica de Madrid (UPM) y Management Solutions, publica su newsletter trimestral correspondiente al 2T25 sobre una aproximación a los sistemas multiagente de GenAI
La Cátedra iDanae, que surge en el marco de la colaboración de la UPM y Management Solutions, tiene el objetivo de promover la generación de conocimiento, su difusión y la transferencia de tecnología y el fomento de la I+D+i en el área de Analytics. En este contexto, una de las líneas de trabajo que desarrolla la Cátedra es el análisis de las metatendencias en el ámbito de Analytics.
GenAI: una aproximación a los sistemas multiagente
Introducción
Los grandes modelos lingüísticos (LLM) son redes neuronales profundas basadas en la arquitectura de transformadores que procesan y generan texto aprendiendo de grandes cantidades de datos. Estos modelos han destacado en tareas como la traducción, el resumen y la creación de contenidos. De hecho, la incorporación de LLMs dentro de algunos sistemas de IA ha permitido desarrollar motores y herramientas capaces de ejecutar tareas, principalmente relacionadas con el uso del lenguaje natural, que no podían realizarse de forma automática, o que superan a los sistemas de IA existentes, cambiando la forma de abordar las tareas de lenguaje natural y ofreciendo nuevas capacidades de razonamiento, generación y recuperación de información.
A medida que estos modelos crecen y se desarrollan nuevas aplicaciones, se han ido integrando cada vez más en sistemas de IA más complejos, incluida la combinación con funcionalidades, como el uso de Retrieval Augmented Generation (RAG), codificadores u otros elementos para realizar mejor las tareas y alcanzar el objetivo.
Sin embargo, la complejidad de las actividades que debe asumir y ejecutar un sistema de IA exige constantemente estructuras más potentes, que combinen conocimientos y capacidades expertas con soluciones de distinta naturaleza. Una opción para abordar este requisito es construir un sistema en el que diferentes agentes (LLM, gestores de bases de datos, intérpretes, modelos, etc.) puedan interactuar entre sí, capitalizando la eficiencia de cada uno, pero garantizando la eficacia del sistema sin comprometer su seguridad.
En esta solución, múltiples agentes autónomos trabajan juntos para resolver problemas, tomar decisiones y alcanzar objetivos. Estos sistemas, denominados "sistemas multiagente" (MAS), imitan la naturaleza colaborativa de las sociedades humanas, aprovechando los puntos fuertes y las capacidades de los agentes individuales para crear una solución más sólida y adaptable. Al permitir a los agentes comunicarse, negociar y coordinar sus acciones, los MAS están allanando el camino para avances en áreas como la robótica, las redes inteligentes y las simulaciones complejas.
Esta publicación pretende explorar cómo los MAS pueden mejorar la calidad, precisión y robustez de los sistemas de IA. Para ello, en la sección 2 se describen los principales componentes técnicos de un MAS, y en la sección 3 se ha desarrollado una aplicación práctica para ejemplificar las posibilidades de estos sistemas y mostrar algunas métricas que pueden utilizarse para medir el rendimiento. Por último, en la sección 4 se incluyen algunas reflexiones sobre los retos de los MAS para las empresas.
Los sistemas multiagente: un breve repaso
Concepto
Un sistema de IA se considera un sistema multiagente (MAS) cuando múltiples agentes autónomos trabajan juntos para resolver problemas, tomar decisiones y alcanzar objetivos. En una versión simple, un MAS se compone de múltiples instancias de LLM (agentes) que trabajan juntos para resolver problemas más complejos, adaptándose a un comportamiento similar al humano para tomar decisiones. Para ello, a cada agente se le asigna un papel en un dominio específico y luego todos los agentes se comunican y cooperan para obtener la mejor respuesta. Por ejemplo, en un MAS de redacción de artículos, un agente podría ser el planificador que recopila el contenido para escribir el artículo, otro agente podría ser el escritor que escribe el artículo, basándose en una base de datos de conocimiento experto, y un tercer agente podría ser el editor que revisa el artículo. Al final, estos tres agentes debaten sobre las respuestas de los demás y cooperan para escribir el mejor artículo posible.
Según la estrategia de comunicación entre agentes, se pueden diseñar diferentes alternativas para que un MAS se estructure:
- Agentes cooperativos: todos los agentes tienen el mismo objetivo. Trabajan juntos e intercambian información para llegar a una solución común.
- Debate o agentes mixtos: cada agente tiene su propio punto de vista u objetivo. Así, argumentan y critican las respuestas de los demás para llegar a una solución común y más afinada.
- Agentes competitivos: son como los agentes de debate, pero compiten por el mejor punto de vista en lugar de acabar en una solución común.
- Agentes jerárquicos: es un enfoque en el que los agentes se organizan en una estructura jerárquica (normalmente un árbol) para mejorar la descomposición de tareas entre ellos. A continuación, los agentes de los nodos padres asignan tareas a los agentes de los nodos hijos.
Construir un MAS
Al construir un MAS pueden diseñarse y desarrollarse varios módulos, para garantizar que todas las funciones se coordinan de forma eficaz:
- Módulo de perfil: se refiere al módulo en el que se asignan los roles a cada agente. Los roles se asignan en la mayoría de los casos manualmente; sin embargo, podrían ser creados y asignados automáticamente por los LLM o extraídos de una base de datos que contenga posibles roles similares a los humanos.
- Módulo de memoria: es necesario para realizar un seguimiento de las consultas de los usuarios y de las generaciones de LLM dentro de un contexto (a corto plazo) o para tener un registro de más información a lo largo del tiempo (a largo plazo). A continuación, la memoria puede almacenarse en diversos formatos y estructuras de datos, como bases de datos, embeddings o incluso lenguaje natural (estructuras legibles por humanos).
- Módulo de planificación: intenta que los agentes adquieran un comportamiento más parecido al humano a la hora de descomponer las tareas para llegar a sus objetivos. Así, la planificación puede ser centralizada, en la que un agente controla el proceso de planificación de todos los agentes, o descentralizada, en la que cada agente planifica su flujo de trabajo de forma independiente. El módulo de planificación puede controlarse mediante retroalimentación. Cuando no hay retroalimentación, las tareas pueden descomponerse y ejecutarse secuencialmente, pueden organizarse en una estructura jerárquica (árboles), o pueden depender de un planificador externo. Si el módulo incluye retroalimentación, ésta puede obtenerse del entorno, de los humanos o de otros agentes o LLMs.
- Módulo de acción: gestiona todas las decisiones y resultados de los agentes. Así, considera cómo se van completando los objetivos, qué herramientas hay que utilizar y cuáles son las consecuencias de las acciones de los distintos agentes.
Aunque la creacion de los MAS ha sido muy reciente, ya se han desarrollado algunos marcos utilizados para construir agentes. A continuación se presentan algunos de los marcos ampliamente utilizados:
- LangGraph: diseñado por Langchain, utiliza un flujo de trabajo basado en grafos acíclicos dirigidos (DAG) para modelar los MAS, en los que las tareas y funciones están contenidas dentro de cada nodo del grafo.
- Autogen: diseñado por Microsoft, se basa en la creación de agentes con diferentes roles. Después, estos agentes cooperan y se comunican entre sí para cumplir sus tareas. Sin embargo, solo admite la memoria a corto plazo, pues únicamente mantiene un registro de las interacciones recientes en la ventana contextual.
- CrewAI: de forma similar a Autogen, se crean agentes con objetivos específicos para alcanzar una meta común. A diferencia de Autogen, CrewAI sí admite memoria a largo plazo, lo que le permite realizar un seguimiento de las interacciones pasadas. Además, está construida sobre LangChain, lo que le permite utilizar y construir herramientas más personalizadas.
Una aplicación práctica: breve exposición
En la Cátedra iDanae se ha desarrollado un sistema MAS para probar distintas arquitecturas. El objetivo del MAS es crear una aplicación experta de preguntas y respuestas, en la que un usuario pueda plantear preguntas sobre la gestión de riesgos ESG para el sector bancario (con especial atención a los riesgos climáticos y medioambientales), incluida la regulación, las técnicas de modelización, los datos utilizados, etc. En esta sección se describen los pasos dados para desarrollar el sistema (desde la creación del conjunto de datos hasta la evaluación), se incluye una comparación con otros enfoques más sencillos y se destacan algunas mejoras en cada etapa.
Desarrollo del sistema
Creación de conjuntos de datos
La base de este MAS es un conjunto de datos estructurado compuesto por preguntas y respuestas (Q&A) sobre la gestión del riesgo ESG. Con este fin, cada entrada del conjunto de datos contiene una pregunta relacionada con diferentes temas sobre la gestión del riesgo ESG y una respuesta basada en la documentación oficial (como las directrices europeas sobre gestión del riesgo de la Autoridad Bancaria Europea, las expectativas de supervisión del BCE), prácticas de modelización aplicadas en el sector bancario, conocimientos científicos sobre técnicas de modelización y ciencia de datos, o información de bases de datos disponibles. Este conjunto de datos se creó y revisó manualmente para facilitar el aprendizaje basado en la recuperación, sirviendo así de referencia para evaluar la precisión de las respuestas generadas por el sistema.
Desarrollo de los RAG
La primera implementación consistió en un sistema RAG básico, que se construyó para recuperar información relevante relacionada con ESG y generar respuestas basadas en los fragmentos recuperados. Siguió las siguientes etapas:
- Creación de la base de datos. Se utilizó Qdrant, una base de datos vectorial de alto rendimiento, para almacenar y recuperar las incrustaciones de documentos. Las directrices y documentos ESG se dividieron en secciones más pequeñas y se almacenaron como vectores incrustados para una recuperación eficiente. Estos vectores se obtuvieron utilizando el modelo all-MiniLM-L6-v2, un modelo de embeddings desarrollado por Microsoft, diseñado para tareas eficientes de búsqueda semántica, agrupación y similitud de textos.
- Procesamiento de consultas. El sistema se creó utilizando Amazon Bedrock de Amazon Web Services (AWS) y el modelo Claude-3-Haiku. A continuación, la entrada de la consulta se convirtió en una representación vectorial y se comparó con los vectores almacenadas para recuperar los fragmentos relevantes y, por último, el modelo generó una respuesta basada en los fragmentos de documentos recuperados.
Una vez creada, con el objetivo de mejorar la precisión de la respuesta, se implementó un RAG avanzada incorporando un modelo de re-ranking (amazon.rerank-v1:0). Tras recuperar varios fragmentos de documentos en función de la consulta, se aplicó el modelo de reordenación. Este modelo asigna puntuaciones de relevancia a cada fragmento en función de la similitud de embeddings. Sólo los fragmentos con puntuaciones superiores a 0,6 se seleccionaron como entrada para el LLM. Este proceso elimina los fragmentos poco relevantes y mejora la precisión contextual de las respuestas.
Desarrollo del MAS
La última mejora fue la creación de un Sistema Multiagente para mejorar la solidez de las respuestas relacionadas con ESG. El MAS se construyó con AutoGen, una herramienta que ayuda a configurar y gestionar agentes con IA que trabajan juntos. Con la configuración GroupChat de AutoGen, los agentes podrán comunicarse fácilmente, compartir tareas y mejorar las respuestas paso a paso.
El planteamiento inicial utilizaba un sistema de agente único con AutoGen para generar respuestas. Este sistema constaba de un único agente responsable de recuperar las respuestas de los documentos. Para ello, el agente utilizaba una herramienta que incluía el modelo reranker para recuperar los documentos ESG relevantes y, a continuación, formulaba una respuesta a la consulta.
A continuación, el sistema se amplió a un MAS utilizando GroupChat de AutoGen, lo que permitió a varios agentes colaborar en un proceso estructurado. El sistema se configuró para funcionar de forma autónoma, es decir, sin intervención humana, y sin permitir que un agente hablara dos veces seguidas, garantizando una participación equilibrada. El MAS consistió en los siguientes agentes respondiendo secuencialmente en el orden dado:
- Herramienta de contexto: recuperación de documentos ESG relevantes de Qdrant mediante RAG y recalificación.
- Investigador: extrajo el contexto y generó una respuesta inicial basada en los datos recuperados.
- Crítico: evaluó la respuesta del investigador, identificando incoherencias o elementos ausentes sin generar una respuesta propia.
- Sintetizador: combinó los comentarios de ambos agentes en una respuesta final concisa y bien estructurada, y se aseguró de que el resultado final fuera conciso, preciso y sin críticas innecesarias.
Retrieval Augmented Generation (RAG)
RAG es una técnica que combina la capacidad de generación de texto de los LLM con la recuperación de información relevante (chunks) de documentos almacenados en una base de datos externa. De este modo, el LLM utiliza los fragmentos recuperados como contexto adicional para generar una respuesta más precisa y/o elaborada, reduciendo así las alucinaciones. El enfoque que siguen los RAG para gestionar estos fragmentos es disponer del llamado recuperador. Este recuperador se compone de dos módulos, uno de construcción y otro de consulta. En el módulo de construcción, los documentos de texto se cortan en fragmentos de una longitud predefinida y, a continuación, cada trozo se codifica en incrustaciones vectoriales (representaciones numéricas de las palabras de cada trozo en función de su contexto y definición) que se almacenan en la base de datos vectorial. A continuación, el módulo de consulta codifica la consulta del LLM en incrustaciones vectoriales y utiliza técnicas de búsqueda de similitudes en los fragmentos incrustados almacenados para encontrar la información que mejor se ajuste a la consulta. Se pueden desarrollar varios tipos de sistemas RAG:
Además, existe un proceso de recuperación adaptativa para los RAG en el que el LLM decide si es suficiente utilizar su propio conocimiento para generar una respuesta o si es necesaria la recuperación del contexto para refinarla. En este contexto, los LLM actúan como agentes autónomos que toman decisiones sobre sus operaciones. 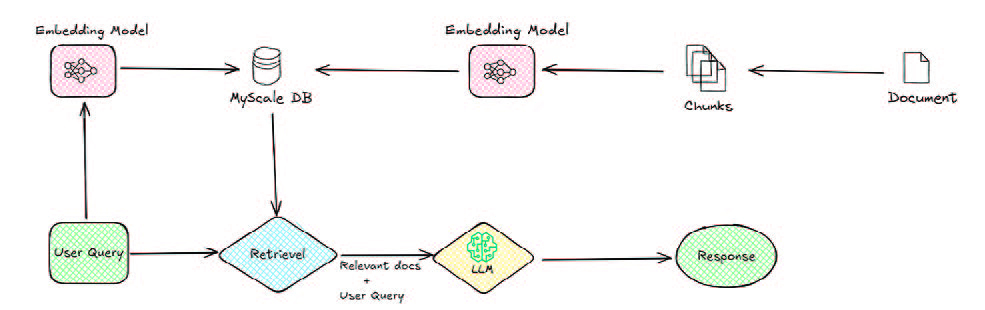 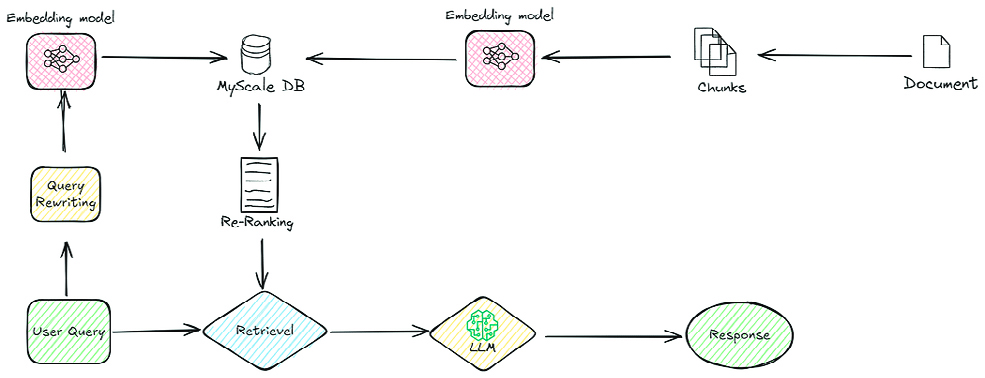 |
Evaluación y resultados
Para evaluar la eficacia de los sistemas RAG y MAS, se aplicó un marco de evaluación estructurado. Se utilizó un LLM para medir automáticamente la similitud entre las respuestas reales del conjunto de datos y las respuestas generadas por los sistemas RAG y MAS. Este ranking de similitud determinó si se estaba recuperando la información más relevante. Además, se calculó la tasa de error de palabras (WER) entre las respuestas reales y las generadas. Esto mide la discrepancia entre una respuesta generada y el texto de referencia midiendo el porcentaje de palabras que deben insertarse, eliminarse o sustituirse para que coincida con la respuesta correcta.
Análisis de los resultados
Se ha llevado a cabo una evaluación, según la estrategia previamente definida, centrada en la eficacia de los sistemas RAG básico y avanzado, monoagente y MAS. A continuación, se han perfeccionado las indicaciones y también se han obtenido y analizado nuevos resultados.
Respuestas similares
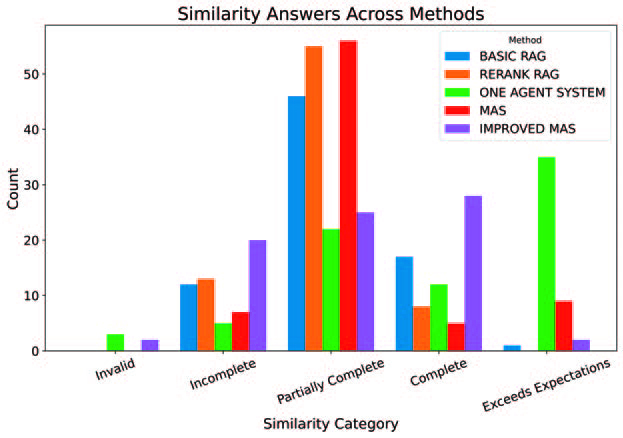
La siguiente figura muestra cómo el LLM que se utilizó para la evaluación de las respuestas clasificó las respuestas de los sistemas. Dividió estas respuestas en cinco categorías: No válidas, Incompletas, Parcialmente completas, Completas y Superan las expectativas. Estas categorías reflejan hasta qué punto la respuesta capta la intención y el contenido de la respuesta de referencia.
El RAG básico generó un gran número de respuestas Parcialmente completas, que carecían de exhaustividad y omitían puntos clave. Una pequeña parte de las respuestas se consideraron Completas, y sólo unas pocas alcanzaron la categoría Excede las expectativas. La presencia de respuestas Incompletas e Inválidas indica que este sistema tiene problemas de coherencia y a menudo no recupera contenidos relevantes.
El RAG avanzado siguió un patrón similar a la RAG básica, con la mayoría de las respuestas clasificadas como Parcialmente Completa. El número de respuestas Completas fue ligeramente inferior al de la versión básica y no hubo respuestas Supera las expectativas. Aunque la reclasificación ayudó a reducir las salidas irrelevantes, las respuestas no fueron tan profundas, es decir, se centraron más sobre todo en el contexto recuperado.
El sistema de agente único mostró una mayor variabilidad. Muchas respuestas se clasificaron como Excede las expectativas, lo que refleja su capacidad para generar respuestas más ricas. Sin embargo, también produjo varias respuestas Parcialmente Completas y Completas, junto con algunas Incompletas o No Válidas. La falta de retroalimentación interna del sistema contribuyó probablemente a esta incoherencia, ya que algunas respuestas estaban bien desarrolladas y otras no llegaban al punto principal.
El MAS mejoró la coherencia de las respuestas en comparación con la configuración de un solo agente. La mayoría de las respuestas seguían siendo Parcialmente Completas, pero aumentaron las Completas y las Que Superan las Expectativas, mientras que las Incompletas e Inválidas fueron mínimas. La colaboración entre agentes, en particular el uso de un Crítico y un Sintetizador, ayudó a mejorar la completitud semántica. Sin embargo, la elevada proporción de respuestas Parcialmente Completas sugiere problemas de coordinación entre agentes.
El MAS mejorado obtuvo los resultados más equilibrados. Produjo una mayor proporción de respuestas completas y redujo el número de resultados incompletos e inválidos. Esta mejora puede atribuirse a la mejora del diseño de las instrucciones y a la mayor claridad de las instrucciones de los agentes, que ayudaron a resolver los problemas de ambigüedad de roles y alineación de tareas.
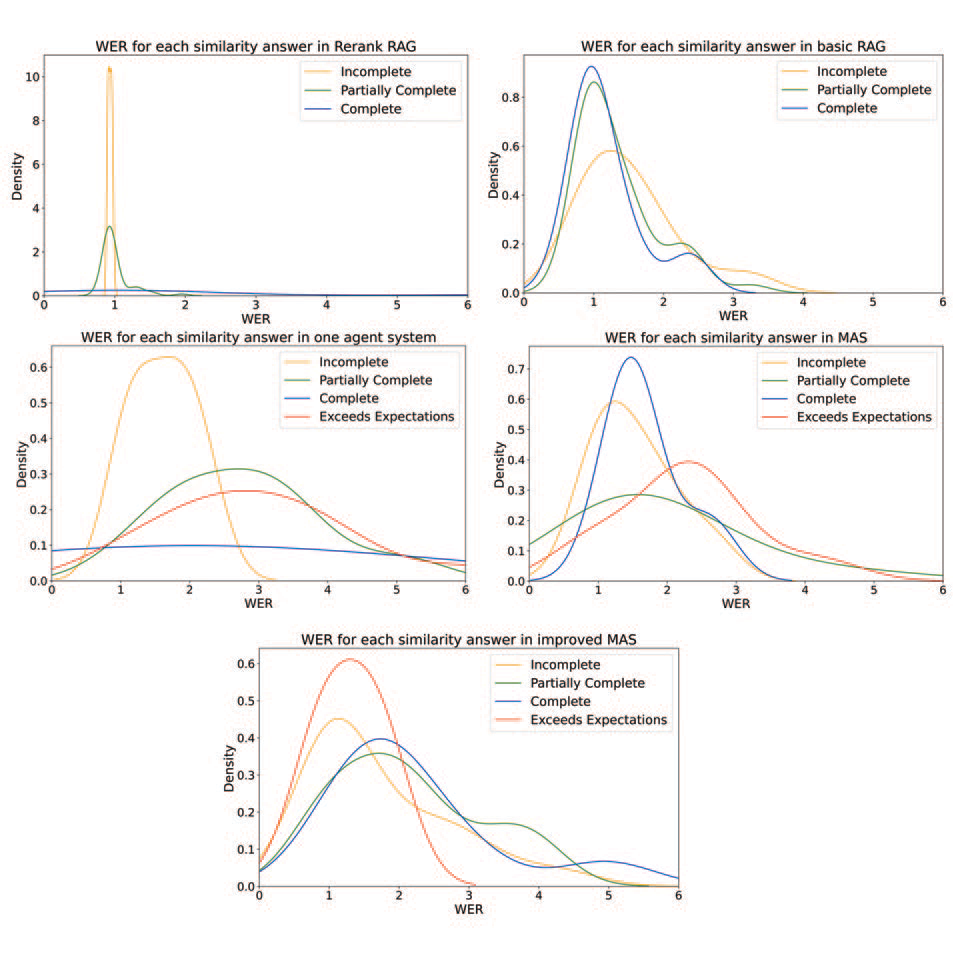
Comparación WER
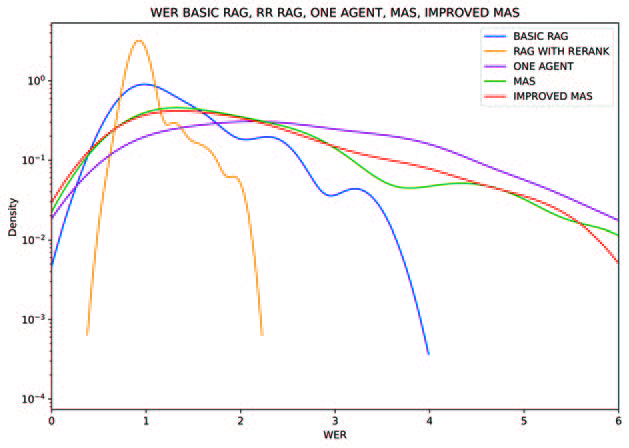
La comparación del RAG básico y la versión recalificada revela diferencias clave en la calidad de los resultados.
- El WER de la RAG básica muestra que el contexto recuperado a veces está poco relacionado con la pregunta, lo que da lugar a respuestas demasiado genéricas o fuera de tema. Como resultado, las respuestas generadas requieren muchas ediciones, lo que da lugar a valores de WER elevados.
- El RAG avanzado muestra un WER más bajo en la mayoría de las respuestas. El proceso de reordenación mejora la relevancia del contexto recuperado, lo que conduce a resultados más precisos. Sin embargo, muchas de estas respuestas carecen de profundidad. En algunos casos, el sistema se limita a reformular el fragmento recuperado sin añadir un razonamiento o una síntesis significativos.
La comparación entre los sistemas basados en agentes pone de relieve el impacto de la retroalimentación interna, la planificación y la definición de funciones.
- El sistema de agente único produce respuestas con un WER moderado. Aunque puede razonar más allá del contenido recuperado, la falta de revisión interna hace que las respuestas contengan a menudo incoherencias o elaboraciones innecesarias. El rendimiento es muy variable, y muchas respuestas requieren una edición significativa para alinearse con la referencia.
- El MAS inicial muestra una clara mejora con respecto a la configuración de un solo agente. El uso de varios agentes con funciones distintas ayuda a detectar antes los problemas y a perfeccionar la respuesta antes del resultado final. Como resultado, los valores de WER son generalmente más bajos. Sin embargo, algunas respuestas siguen siendo incoherentes.
- El MAS mejorado consigue el mejor rendimiento WER entre todos los MAS. El perfeccionamiento rápido conduce a una definición más clara de las tareas y a una mejor cooperación entre los agentes. Esta configuración ayuda a evitar interpretaciones erróneas y contenidos innecesarios, lo que se traduce en respuestas concisas y precisas. Sin embargo, debido a sus capacidades de razonamiento más complejas, este sistema sigue siendo superado por el RAG avanzado.
El análisis anterior muestra que los sistemas con más respuestas Excede las expectativas, como las configuraciones de agente único y MAS, no consiguen el WER más bajo. El RAG avanzado, a pesar de tener en su mayoría respuestas Parcialmente Completas y ninguna Excede las Expectativas, consigue una mejor WER que el MAS mejorado. Esto sugiere que producir respuestas más completas no se corresponde directamente con requerir menos ediciones. Para analizar y comprender mejor cómo se relaciona la calidad semántica con la precisión estructural, se analizaron todas las distribuciones del WER en las distintas categorías de similitud de forma independiente, obteniéndose las siguientes conclusiones:
- El RAG básico muestra valores de WER similares en las categorías Incompleta, Parcialmente completa y Completa, sin diferencias claras entre ellas. Esto sugiere que incluso cuando las respuestas parecen semánticamente más sólidas (como las clasificadas como Completas), siguen requiriendo una edición considerable. La falta de diferenciación se debe probablemente a una recuperación de documentos genérica y mal estructurada.
- El RAG avanzado presenta un escenario diferente, en el que las respuestas Incompletas tienen un WER notablemente inferior en comparación con las categorías Parcialmente Completas y Completas. Esto se debe a que las respuestas incompletas son muy cortas y se asemejan mucho a las respuestas de referencia en un determinado nivel de tokens, a pesar de su inadecuación semántica. El WER de las respuestas más completas aumenta bruscamente, lo que demuestra que cuando las respuestas son más detalladas se producen con frecuencia desajustes estructurales.
- Del mismo modo, el sistema de un solo agente produce respuestas Incompletas con valores de WER
sistemáticamente bajos. Sin embargo, a medida que mejora la completitud semántica (de Parcialmente completa a Completa y Supera las expectativas), el WER aumenta notablemente. Este patrón indica que las respuestas más ricas y elaboradas a menudo divergen de las respuestas de referencia, lo que sugiere que el sistema tiene dificultades para razonar y estructurar de forma coherente. - En el MAS inicial, las respuestas Completas y Supera las expectativas tienen un WER relativamente más alto que las Parcialmente completas y, sobre todo, las Incompletas. El mayor WER de las respuestas más elaboradas, además de deberse probablemente a la descoordinación de los
agentes, pone de manifiesto una vez más el hecho de que las respuestas más detalladas contienen más desajustes estructurales. - El MAS mejorado presenta la relación más equilibrada entre similitud y WER. A diferencia de los demás sistemas, las respuestas Excede las expectativas no son las que arrojan el mayor WER. De hecho, tienden a tener valores de WER más bajos que las respuestas Incompletas, lo que indica que el sistema es capaz de producir respuestas semánticamente ricas y detalladas al tiempo que mantiene una fuerte
alineación estructural. A pesar de que el WER de las respuestas Incompletas es inferior al de las Completas y Parcialmente completas, el refinamiento de prompt demostró mejorar la claridad de los roles y la coordinación entre los agentes.
Estos resultados reflejan varios de los modos de fallo identificados en Cemri. En el MAS inicial, la elevada proporción de respuestas Parcialmente Completas y el aumento de el WER para las respuestas Completas y Excede las Expectativas apuntan a problemas relacionados con la descoordinación de los agentes, como el desajuste razonamiento-acción o que los agentes ignoren las aportaciones de los demás. Estos problemas son coherentes con los fallos de desalineación entre agentes descritos en el artículo. Por otro lado, los MAS mejorados mostraron respuestas más coherentes y un mejor rendimiento WER, lo que puede relacionarse con un diseño más claro de las instrucciones y una mejor especificación de las tareas. Estos cambios ayudaron a reducir fallos como la desobediencia a las especificaciones de roles y la terminación incorrecta, que se observaron con frecuencia en otras configuraciones de MAS del estudio. Aunque el artículo subraya que el ajuste de las instrucciones no suele bastar para resolver problemas más profundos del sistema, las mejoras observadas sugieren que incluso pequeñas mejoras en la claridad de las funciones y la comunicación pueden conducir a un comportamiento más fiable de los agentes y a mejores resultados generales.
Retos para las organizaciones
Implantar MAS en el entorno corporativo es un objetivo interesante porque dicho sistema podría interactuar con los datos de la organización de forma autónoma, ejecutar acciones sin supervisión e incluso ser un método de gestión de datos para clientes o empleados que proporcione un mejor producto o servicio. Todas estas ventajas se traducen en una reducción de los costes operativos y una mejora de la satisfacción del cliente.
Sin embargo, esto plantea una serie de retos empresariales que pueden repercutir significativamente en el éxito de tales iniciativas:
- Complejidad de la integración con los sistemas heredados existentes. Muchas empresas cuentan con infraestructuras informáticas profundamente arraigadas en sus operaciones, por lo que la integración de MAS con estos sistemas puede ser técnicamente exigente y costosa.
- Gestión de la privacidad y seguridad de los datos. Los sistemas multiagente a menudo implican el intercambio de grandes volúmenes de datos entre agentes, que pueden incluir información corporativa sensible. Garantizar que estos datos se transmiten y almacenan de forma segura es primordial para evitar infracciones y mantener el cumplimiento de la normativa de protección de datos.
- Escalabilidad y optimización del rendimiento. A medida que aumenta el número de agentes en un sistema, garantizar que el sistema siga siendo escalable y funcione eficientemente puede suponer un reto. Cada agente requiere recursos informáticos, y las interacciones entre agentes pueden volverse complejas y consumir muchos recursos.
- Lagunas en cuanto a competencias y conocimientos. La implantación y gestión de sistemas multiagente requiere conocimientos y habilidades especializados que pueden no estar fácilmente disponibles entre la mano de obra existente. Las empresas pueden tener dificultades para encontrar y retener personal cualificado que domine las tecnologías MAS.
- Coordinación y resolución de conflictos. En un sistema multiagente, los agentes a menudo tienen que trabajar juntos para lograr objetivos comunes. Sin embargo, coordinar las acciones de múltiples agentes autónomos puede resultar difícil, sobre todo cuando sus objetivos o estrategias entran en conflicto.
- Cumplimiento de los reglamentos y normas específicos del sector. Los distintos sectores se rigen por diversas normativas y estándares que dictan cómo deben tratarse, procesarse y almacenarse los datos. En Europa, la implantación de sistemas multiagente también debe cumplir el AI Act, una normativa exhaustiva destinada a garantizar el despliegue seguro y ético de los sistemas de IA. El AI Act impone requisitos estrictos a los sistemas de IA de alto riesgo, incluidas pruebas rigurosas, documentación y medidas de transparencia.
Conclusiones
Los grandes modelos lingüísticos (LLM) han revolucionado el procesamiento del lenguaje natural al mejorar las capacidades de razonamiento, generación y recuperación de información. A medida que estos modelos se expanden, se integran cada vez más en sistemas complejos como el Retrieval Augmented Generation (RAG) y los Sistemas Multiagente (MAS), en los que participan múltiples agentes autónomos que colaboran para resolver problemas y tomar decisiones.
Esta newsletter explora el concepto de RAG a través de una sencilla aplicación de preguntas y respuestas que utiliza estos enfoques. Se ha complementado un sistema básico de RAG con otro avanzado, pero ninguno de ellos lograba respuestas completas, lo que daba lugar a que faltaran puntos clave, a pesar de los esfuerzos por mejorar la relevancia. El sistema MAS fue más coherente, con más respuestas completas y excelentes y menos inválidas, gracias a un mejor trabajo en equipo de los agentes, mejores instrucciones y funciones más claras para los agentes.
No obstante, a pesar de que estas técnicas mejoran el rendimiento de los sistemas GenAI, aún quedan varios retos por delante, como la complejidad para la integración con los sistemas heredados existentes, la seguridad, la privacidad de los datos, o elementos técnicos como la escalabilidad, el rendimiento o la resolución de posibles conflictos entre agentes, entre otros. Habrá que seguir abordando estos elementos para un uso profesional de estos nuevos sistemas.
La newsletter “GenAI: una aproximación a los sistemas multiagente" ya está disponible para su descarga en la web de la Cátedra tanto en español como en inglés.