Auto Machine Learning, towards model automation
A mathematical model is, in a way, a simplification of reality that takes advantage of the information available to systematize decision-making. This simplification allows hypotheses on the behavior of both variables and systems to be evaluated through their summary representation under a set of postulates, usually based on data and applying inference criteria. Its main purpose is to explain, analyze or predict the behavior of a variable.
Auto Machine Learning
The current revolution in modeling techniques, coupled with increased computing power and more accessible and greater data storage capacity, has radically changed the way models have been built in recent years. This revolution has been a key factor that has stimulated the use of these new techniques not only in decision-making processes where traditional approaches were used, but also in areas where the use of models was not so common. Finally, in some industries, such as the financial sector, the use of models has also been driven by regulation. Standards such as IFRS 9 and 13 or Basel II have promoted the use of internal models with the aim of adding sensitivity and making the calculation of accounting impairment or financial risks more sophisticated.
Although it may appear otherwise, the most common modeling techniques currently used in the business field do not have a recent origin. Specifically, linear and logistic regressions date from the 19th century. However, for some time now there have been significant developments in new algorithms that, while aimed at enhancing how patterns are found in the data, also introduce new challenges such as the need for improved interpretability techniques. The use of these new mathematical models in computing is a scientific discipline known as machine learning, since it allows systems to learn and find patterns without being explicitly programmed to do so.
There are multiple definitions of machine learning, two of the most illustrative being those of Arthur Samuel and Tom Mitchell. For Arthur Samuel , machine learning is "the field of study that gives computers the ability to learn without being explicitly programmed", while for Tom Mitchell it is "a program that learns from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks T, as measured by P, improves with experience E”. These two definitions are usually related to unsupervised and supervised learning, respectively.
As a consequence, the appetite to properly understand and draw conclusions from data has increased dramatically. However, at the same time, implementing these methods has required changing multiple aspects in organizations and is, in turn, a source of potential risk due to development or implementation errors or inappropriate use.
Advanced modeling improves business and operational processes, or even facilitates the emergence of new business models. An example can be found in the financial sector, where new digitization methodologies are modifying the current value proposition, but also adding new services. According to a survey conducted by the Bank of England and the Financial Conduct Authority on almost 300 companies in the financial and insurance sectors, two thirds of the participants used machine learning in their processes. Machine learning techniques are frequently used in typical control tasks, such as money laundering prevention (AML) or fraud detection, the analysis of cybersecurity-related threats, and in business processes such as customer classification, recommendation systems or customer service through the use of chatbots. They are also used in credit risk management, pricing, operations and insurance underwriting.
Other sectors have seen a similar level of development. The use of machine learning models is common in industries such as manufacturing, transportation, medicine, justice or the retail and consumer goods sectors. This has caused investment in companies dedicated to artificial intelligence to increase from a total of $ 1.3 billion in 2010 to $ 40.4 billion in 2018. The expected return justifies this investment: 63% of companies that have adopted Machine Learning models have reported increased revenues, with approximately half of them reporting an increase exceeding 6%. Likewise, 44% of companies reported cost savings, with approximately half of them achieving savings over 10%.
Of the different changes made by organizations to adapt to this new paradigm, talent recruitment and retention is still central. To begin with, companies have needed to enlarge their teams specializing in machine learning. The demand for professionals in this field increased by 728% between 2010 and 2019 in the United States, with a qualitative change in the demand for general data scientist skills and knowledge also being notable.
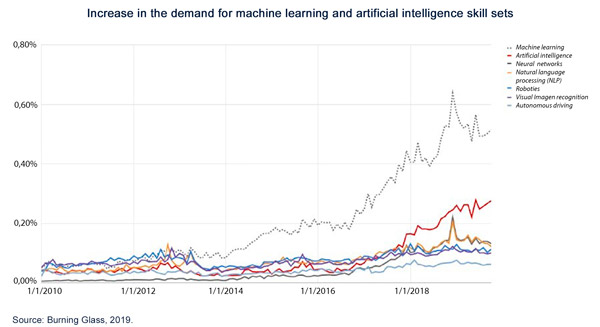
But this demand for generic machine learning and data scientist skills is not always the case: in order to analyze the increasing amounts of data available using increasingly sophisticated tools, requirements for skills have become more specific to include knowledge of different programming languages such as Python, R, Scala or Ruby, the ability to deal with databases in big data architectures, knowledge of cloud computing, advanced mathematical and statistical knowledge, and specialized postgraduate training. Consequently, many different jobs in the market have become hard to fill due to their highly specific skill set requirements. In addition, the rate at which companies are generating data means that, even with a stable supply of data scientists, the current recruitment solution is not scalable.
However, it is not only necessary to have specialist teams, but also to implement new development procedures, review validation methods, revise and assess models in the validation and audit areas, and make important cultural changes in other areas for this implementation to be effective. The use of these new processes creates a chain reaction that affects the entire model life cycle, including notably the identification, management and governance of model risk. Many of these models also require supervisory approval, as in the financial industry (e.g. capital or provision models), or in the pharmaceutical industry, which adds new challenges such as the need to ensure the interpretability of the models used, as well as to develop other elements of model confidence.
Another notable aspect of the investment in machine learning methods is that its development is uneven across organizations: the need to undergo validation, audit and approval processes established by regulations, or the requirement to maintain specific documentation standards, is creating differences in the implementation of internal models across firms. According to the EBA’s big data and analytics report, financial institutions are adopting digital transformation programs or promoting the use of machine learning techniques in areas such as risk mitigation (including automated scoring, operational risk management or fraud) and Know Your Customer processes. However, "although the use of machine learning may represent an opportunity to optimize capital, from a prudential framework perspective it is premature to consider the use of machine learning techniques appropriate for determining capital requirements”.
There are also operational risks that are difficult to detect, such as those arising from human error during model implementation, or those related to data storage security, which should be properly managed to ensure machine learning systems are used in a suitable environment. An example of this is the framework established by the European Commission in these cases, covering different aspects of the modeling process. Finally, and also due to both regulatory and management considerations, models need to operate reliably and be used ethically so that they can be trusted in the decision-making process. The EBA’s proposal in this regard, based on seven pillars of trust, is of particular interest: ethics, interpretability, avoidance of bias, traceability, data protection and quality, security and consumer protection. These issues have also been identified as key elements by universities and business spheres.
In this context, different model development tasks demand very different times: the tasks prior to and complementary to analysis also require a large amount of time and resources to prepare, clean and generally process the data; 60% of a data scientist's time is spent cleaning data and organizing information, while 9% and 4% of their time is spent on knowledge discovery tasks and algorithm tuning, respectively. All this drives the need to change the way in which model development, validation and implementation is approached, to take advantage of the new techniques while solving the difficulties associated with their use, as well as mitigating any potential risks.
For the reasons outlined above, there is a clear trend towards automating processes related to the use of advanced analytics techniques – generally called automated machine learning or AutoML, whose aim is not only to automate those tasks where heuristic processes are limited and easily automatable, but also to allow for more automated, ordered and traceable algorithm and pattern search processes to be generated. According to Gartner, more than 50% of data science tasks will be automated by 2025.
Furthermore, this trend towards automation offers a number of opportunities, such as the ones offered by the automation systems architecture in terms of workflow design model inventory, or component validation. Automated machine learning systems integrate various tools to develop models, also reducing cost, development time and system implementation errors.
AutoML systems and methods seek, among other things, to:
- reduce the time spent by data scientists on developing models through the use of machine learning techniques, and even to allow non-data scientist teams to develop machine learning algorithms;
- improve model performance, as well as model traceability and comparability against manual hyperparameter search techniques;
- challenge models developed using other approaches;
- leverage the investment made in terms of both time and resources to develop codes and improve the system’s components efficiently and with greater traceability;
- and simplify the validation of models and facilitate their planning.
Against this backdrop, this document aims to describe the key elements of AutoML systems. For this purpose, it has been structured in three sections, with three objectives:
- In the first section, the factors explaining the move towards the automation of machine learning processes are analyzed, as are the reasons underlying the development of AutoML systems, through both their componentization and automation.
- The second section provides a descriptive view of the main AutoML frameworks, and explains what approaches are being followed, both in the academic field and in practical experiences aimed at automating modeling processes through machine learning techniques.
- Finally, the third section aims to illustrate the results of AutoML system development, presenting as a case study a competition organized by Management Solutions in early 2020. The aim of this competition, aimed at MS professionals, was to design an Automated Machine Learning model.
For more information, access the full document in pdf (also available in Spanish and Portuguese).
Related documents: Machine Learning, a key component in business model transformation | Data science and the transformation of the financial industry | Model Risk Management: Quantitative and qualitative aspects