Tendencias en IA
Gobierno de la IA e impacto en personas
Vídeo: Tendencias en IA
Índice de la publicación
Documento completo
Acceder a GenMS™ Sybil
La adopción acelerada de la IA plantea un desafío que trasciende lo tecnológico: cómo gobernar sistemas que evolucionan más rápido que las estructuras organizativas, cómo transformar roles profesionales cuando las tareas cambian trimestralmente, y cómo preservar el juicio humano en decisiones críticas mientras se delega la operación rutinaria a sistemas autónomos.
Este bloque aborda la dimensión organizativa y humana de la IA: los modelos de gobierno corporativo que están emergiendo para controlar la IA de extremo a extremo, las prácticas operativas avanzadas que permiten industrializar su despliegue (MLOps, LLMOps), la transformación de roles y perfiles profesionales que ya está en marcha, la adopción sectorial que convierte la IA en infraestructura transversal, el impacto en la vida cotidiana de las personas más allá del trabajo, los desafíos de sostenibilidad e impacto social que introduce, y los marcos éticos operativos que deben traducir principios abstractos en controles concretos y auditoría continua. La pregunta no es si la IA transformará las organizaciones y las personas, sino si seremos capaces de gobernar esa transformación con rigor, velocidad y responsabilidad.
Gobierno corporativo de la IA
La IA desborda los marcos tradicionales
Los modelos de gobierno corporativo tradicionales fueron diseñados para tecnologías predecibles: sistemas que ejecutan lógica determinista, operan dentro de límites definidos y se comportan de forma reproducible. La IA rompe todas estas premisas: toma decisiones sin intervención humana, produce outputs diferentes ante el mismo input, opera mediante procesos internos opacos que sus propios desarrolladores no comprenden por completo, y depende críticamente de proveedores externos cuyos modelos evolucionan sin control directo de la organización. Las estructuras tradicionales de gobernanza tecnológica resultan insuficientes. Los comités de arquitectura y los ciclos de aprobación anuales son demasiado lentos para la velocidad de innovación en IA, carecen del expertise necesario para evaluar sus riesgos específicos, y no están diseñados para gestionar la incertidumbre inherente a sistemas que aprenden y cambian. La pregunta estratégica es cómo gobernar la IA sin frenar la velocidad de adopción y sin acumular riesgo ingobernable.
Organización: roles y estructuras que emergen
Las organizaciones están creando funciones ejecutivas especializadas, aunque con avance heterogéneo. Emerge la figura del Chief AI Officer (CAIO), Chief Data and AI Officer (CDAIO), o equivalente, y se estima que un 26% de las grandes organizaciones ya disponen de este rol. En organizaciones más maduras, el CDAIO reporta directamente a presidencia, con una estructura matricial muy fuerte en países y negocios; en otras, el liderazgo recae en el CTO/CIO o Chief Innovation Officer.
Por debajo del nivel ejecutivo emergen roles especializados todavía sin estandarización: AI Risk Manager, AI Ethics Officer, AI Compliance Lead o Responsible AI Lead. Estos perfiles suelen reportar a las funciones de segunda línea, pero sus responsabilidades, autoridad y recursos varían sustancialmente entre organizaciones.
En primera línea se consolida el Centro de Excelencia de IA, equipos transversales que centralizan conocimiento técnico (LLMs, arquitecturas multiagente, frameworks), infraestructura compartida (plataformas cloud, GPUs, licencias), emisión de guías y estándares, y consultoría interna a líneas de negocio. Operativamente, domina el modelo hub & spokes: un Centro de Excelencia central establece capacidades transversales, mientras equipos descentralizados en líneas de negocio desarrollan soluciones específicas, reportando jerárquicamente a sus superiores, pero con reporte funcional cruzado al hub. Esta estructura permite velocidades diferentes según la madurez de cada línea manteniendo coherencia arquitectónica.
En segunda línea, la madurez organizativa es notablemente menor. Mientras la primera línea ha consolidado estructuras, la segunda presenta alta variabilidad, y hay un debate conceptual abierto sobre si «AI Risk» constituye un riesgo autónomo en la taxonomía corporativa o un amplificador transversal de riesgos existentes. Muy pocas organizaciones lo definen como riesgo de primer nivel (como decisión táctica para asegurar visibilidad y presupuesto); más frecuentemente, aparece como riesgo de segundo nivel dentro de Riesgo de Modelo o Riesgos No Financieros. Otras rechazan incluirlo formalmente y tratan la IA como un amplificador transversal de riesgos existentes (riesgo de modelo aumentado, riesgo de proveedor aumentado, riesgo tecnológico con vulnerabilidades adicionales…), reforzando marcos ya vigentes en lugar de crear taxonomías nuevas.
Independientemente del debate taxonómico, emerge operativamente una función pequeña de coordinación, llamada «AI Risk» o «AI Governance», que orquesta las evaluaciones de riesgo por parte de las funciones especializadas: Riesgo de Modelo valida los modelos, Riesgo Tecnológico evalúa la infraestructura, Ciberseguridad analiza las vulnerabilidades específicas de la IA, Data Protection verifica la privacidad, Legal evalúa la propiedad intelectual, Compliance verifica el cumplimiento regulatorio, etc.
Órganos de gobierno: del comité formal al working group operativo
Prácticamente todas las organizaciones sistémicas han constituido un Comité de Inteligencia Artificial con composición cross-línea de defensa: primera línea (innovación, analytics, datos, tecnología…), segunda línea (riesgo de modelo, riesgo operacional, ciberseguridad, protección de datos, vendor risk, legal, compliance…), y tercera línea (Auditoría como observador). La co-presidencia suele recaer en un responsable de primera y uno de segunda línea.
Sin embargo, el gobierno no ocurre solo en el comité. Por debajo suele existir una estructura informal pero crítica: un AI Working Group compuesto por quienes reportan directamente a los miembros del comité. Preparan materiales, consensúan posiciones, resuelven conflictos. Los temas llegan al comité «for information» o «for approval», no para debate desde cero. El verdadero gobierno (la negociación, el consenso, la resolución de tensiones entre velocidad y control) ocurre en esta capa pre-decisional donde primera y segunda línea construyen acuerdos operativos antes de la sanción formal.
Arquitectura de marcos de riesgo: columna vertebral y uplifting sectorial
Las organizaciones no reinventan sus marcos de riesgo desde cero. Se observa una arquitectura de dos niveles: una columna vertebral central específica de IA (una política de IA breve, que establece principios, alcance, roles, clasificación de riesgos y procesos de aprobación; y un procedimiento de IA que describe exhaustivamente el ciclo de vida desde ideación hasta producción), y sobre todo el uplifting de marcos específicos existentes.
El uplifting consiste en complementar los marcos vigentes añadiendo capítulos específicos de IA. El marco de Riesgo de Modelo incorpora validación de IA generativa, técnicas de explicabilidad (SHAP, LIME, attention mechanisms), detección de sesgos y alucinaciones, monitorización de drift, etc. El marco de Riesgo de Proveedor añade due diligence sobre proveedores de LLMs, certificaciones requeridas, SLAs específicos, planes de contingencia o exit strategies. El marco de Protección de Datos incluye evaluaciones de impacto específicas para IA, minimización de datos en sistemas de IA o ejercicio de derechos GDPR cuando el procesamiento involucra IA. El marco de Compliance implementa el AI Act: clasificación de riesgo, registro, documentación, etc.
Esta arquitectura aprovecha la infraestructura que funciona, asigna responsabilidades claras y mantiene coherencia sin fragmentación. Sin embargo, algunos desafíos técnicos son genuinamente nuevos. Explicar redes neuronales profundas con transformers y trillones de parámetros requiere técnicas especializadas que no existían en la validación de modelos tradicionales. Las funciones de Riesgos están desarrollando estas capacidades en tiempo real.
Clasificación de riesgos y ciclo de vida
El AI Act europeo establece una clasificación (prohibido, alto riesgo, riesgo limitado, riesgo mínimo), necesaria pero insuficiente para el gobierno corporativo de las compañías. La regulación está concebida para proteger a la sociedad y los derechos fundamentales, no a las organizaciones frente sus propios riesgos operacionales, reputacionales o financieros.
Por ello, las organizaciones convergen hacia clasificaciones de riesgo de la IA internas más exigentes, que integran criterios regulatorios con propios: impacto reputacional, criticidad del proceso, clasificación de ciberseguridad, tier del modelo según validación, impacto financiero directo, madurez de proveedores, etc. Un sistema puede no ser alto riesgo regulatorio, pero sí serlo internamente si afecta a procesos críticos o genera una exposición reputacional masiva (Fig. 4).
La clasificación determina las consecuencias operativas. Por ejemplo, alto riesgo implica un análisis exhaustivo de todas las funciones de riesgo, la aprobación formal en Comité, documentación completa, validación independiente, monitorización intensiva, etc.; mientras que bajo riesgo suele implicar un fast track, análisis ligero y elevación al Comité solo para información. El fast track es un elemento crítico, porque resuelve la tensión entre velocidad y control: los sistemas de IA evidentemente de bajo riesgo se aprueban sin demoras, mientras se concentran los recursos de control en los sistemas de IA críticos.
Figura 4. Ejemplo de clasificación interna de riesgos de una compañía más allá de la regulación.
 |
Inventario y trazabilidad
Las organizaciones están obligadas por regulación a mantener un registro único de todos los sistemas de IA desplegados, incluyendo su clasificación de riesgos y estado en el ciclo de vida. Este inventario debe ser completo, actualizado y accesible para supervisores, auditores y funciones de riesgo.
La mayoría de las organizaciones converge hacia expandir el inventario de Riesgo de Modelo, bajo la lógica de que los sistemas de IA requieren validación cuando comportan un riesgo de modelo relevante. Alternativamente, algunas organizaciones expanden el inventario de activos tecnológicos.
El gobierno corporativo de la IA está en maduración acelerada. Los próximos años verán una consolidación hacia mejores prácticas, pero la aceleración de la evolución tecnológica es tal que probablemente continuará tensionando las estructuras organizativas actuales, que fueron diseñadas para paradigmas más lentos.
Industrialización de la IA (MLOps, LLMOps)
De la experimentación a la producción
En el momento actual, el principal cuello de botella en la adopción real de la IA no es algorítmico, sino operativo. Durante años, organizaciones de todo tipo han desarrollado sistemas de IA prometedores en entornos experimentales que nunca llegaron a producción, o que, una vez desplegados, fallaron al enfrentarse a datos reales, perdieron rendimiento con el tiempo o generaron costes y riesgos inasumibles. La industrialización de la IA surge precisamente para cerrar esta brecha entre la experimentación y el uso sostenido en entornos productivos.
Machine Learning Operations (MLOps) emerge como respuesta estructurada a este problema. Puede entenderse como «un conjunto de procesos estandarizados y capacidades tecnológicas para construir, desplegar y operacionalizar sistemas de ML de forma rápida y confiable». MLOps articula procesos y capacidades técnicas para gestionar de forma integrada la preparación de datos, la experimentación, el entrenamiento, la validación, el despliegue, la monitorización y el reentrenamiento continuo de modelos. El objetivo no es únicamente acelerar la puesta en producción, sino garantizar fiabilidad, reproducibilidad, control de riesgos y sostenibilidad operativa a lo largo del tiempo.
La irrupción de la IA generativa amplía este reto de forma significativa. Large Language Model Operations (LLMOps) no sustituye a MLOps, sino que lo extiende para gestionar sistemas con propiedades radicalmente distintas. Los grandes modelos de lenguaje introducen comportamiento no determinista, dependencia crítica de la formulación de prompts, arquitecturas internas opacas con miles de millones o billones de parámetros, y nuevos vectores de riesgo como alucinaciones, generación de contenido no veraz o ataques específicos mediante manipulación de entradas. Estas complejidades se intensifican en sistemas agénticos, donde una única interacción del usuario puede desencadenar cadenas de razonamiento, múltiples llamadas internas al modelo y ejecución autónoma de herramientas externas.
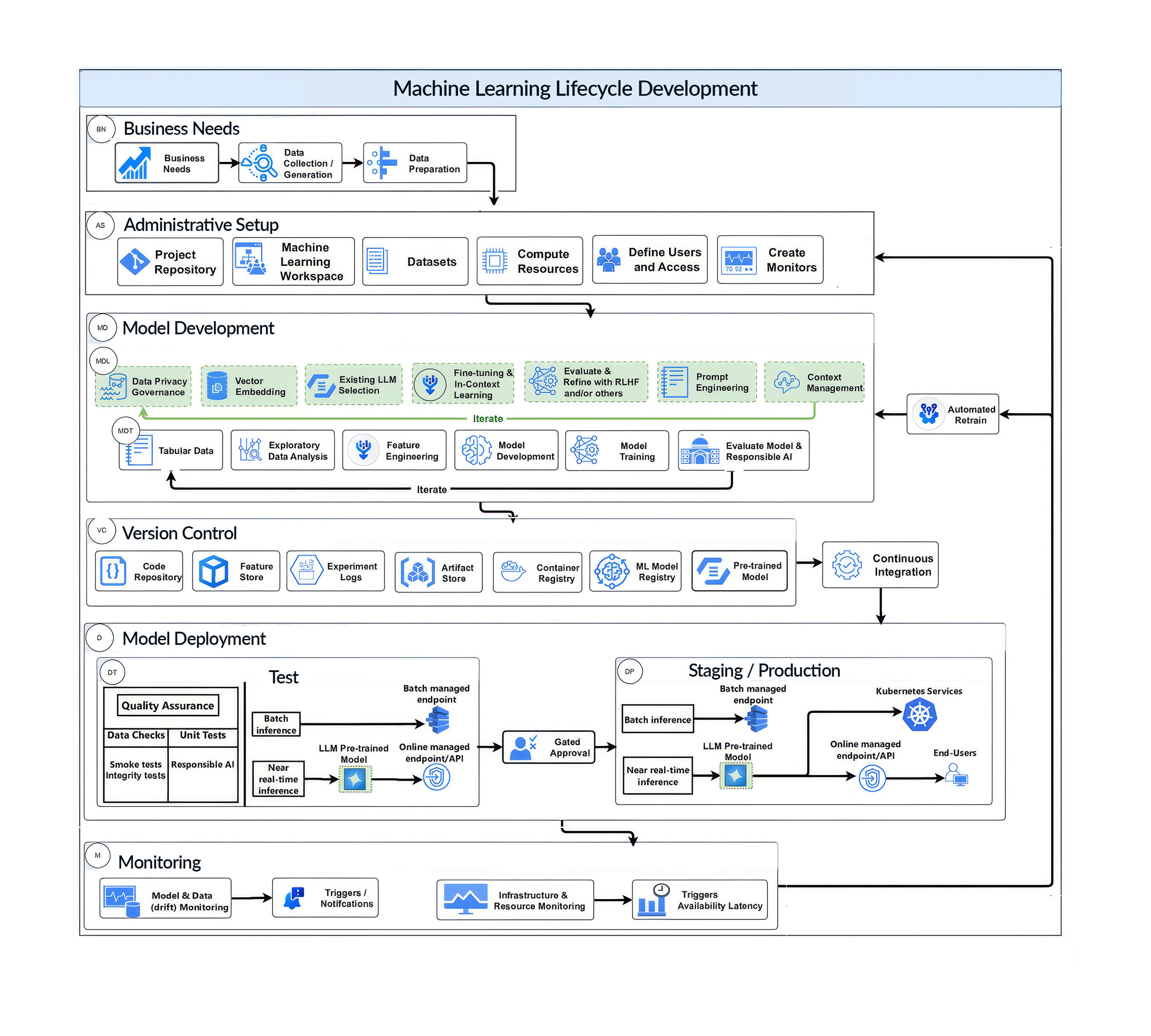
Arquitectura del ciclo de vida MLOps/LLMOps
La industrialización efectiva de la IA requiere una visión integral del ciclo de vida operativo, que diferentes autores expresan de distintos modos (Fig. 5), pero con elementos comunes:
En la fase de preparación de datos, MLOps se centra en la construcción de pipelines robustos para la ingesta, limpieza, transformación y versionado de datos estructurados, garantizando trazabilidad y calidad. LLMOps amplía este alcance al trabajar con grandes volúmenes de datos no estructurados (texto, código, documentos o imágenes) y con representaciones vectoriales utilizadas en arquitecturas de retrieval-augmented generation (RAG). A ello se suman requisitos estrictos de minimización de datos personales, control de fuentes y cumplimiento de marcos de privacidad como GDPR.
Durante la experimentación y el desarrollo, MLOps proporciona mecanismos para rastrear experimentos, comparar modelos, gestionar hiperparámetros y asegurar la reproducibilidad de resultados. En LLMOps, esta fase incorpora nuevas dimensiones: gestión versionada de prompts, evaluación de distintas configuraciones de modelos fundacionales, fine-tuning o adaptación mediante técnicas como LoRA, y diseño de métricas que capturen aspectos cualitativos de la generación, como coherencia, factualidad, seguridad o adecuación al contexto. Estas métricas no sustituyen a las cuantitativas tradicionales, sino que las complementan allí donde el rendimiento ya no puede medirse únicamente con precisión o error.
La validación constituye uno de los puntos de mayor divergencia entre ambos enfoques. Mientras que en MLOps la validación se apoya en tests automatizados sobre conjuntos de datos de referencia para evaluar precisión, sesgo y robustez, en LLMOps resulta imprescindible integrar validación humana en el loop. La evaluación de salidas generativas exige revisión experta, técnicas de fact-checking contra fuentes confiables, pruebas de estrés semántico y ejercicios de red-teaming diseñados para identificar comportamientos no deseados o vulnerabilidades explotables. La validación deja de ser un evento puntual para convertirse en un proceso continuo.
En la fase de despliegue, MLOps se apoya en pipelines CI/CD relativamente maduros, con versiones bien definidas de modelos y dependencias. LLMOps, en cambio, debe gestionar despliegues de modelos de gran escala con implicaciones significativas de infraestructura, latencia y coste. Esto incluye selección dinámica de modelos en función del caso de uso, del nivel de riesgo o del presupuesto, así como la orquestación de sistemas complejos en los que múltiples modelos y agentes interactúan entre sí de forma coordinada.
La monitorización es crítica en ambos paradigmas, pero con énfasis distintos. MLOps se centra en detectar drift de datos o de concepto, degradación de rendimiento, errores y problemas de latencia. LLMOps añade la necesidad de monitorizar costes por token en tiempo real (un factor determinante para la viabilidad económica), identificar patrones de uso no previstos (prompt drift), y mantener trazabilidad completa de interacciones para análisis forense, auditoría y supervisión regulatoria. Sin esta visibilidad, los sistemas generativos pueden escalar rápidamente en complejidad y coste sin un control efectivo.
Finalmente, la gobernanza y el cumplimiento normativo atraviesan todo el ciclo de vida. En MLOps, esto implica documentar el linaje de datos y modelos, definir responsabilidades claras y asegurar controles de calidad. En LLMOps, estas exigencias se amplían para dar respuesta a marcos regulatorios emergentes como el AI Act, incluyendo inventarios de sistemas clasificados por nivel de riesgo, mecanismos de supervisión humana y estrategias de explicabilidad adaptadas a modelos que funcionan como cajas negras.
Figura 5. Ejemplo de fases de MLOps y LLMOps. Fuente: Stone (2025)
 |
Integración con marcos de gobernanza
MLOps y LLMOps no son disciplinas puramente técnicas ni pueden operar de forma aislada. Constituyen la capa operativa que materializa los principios definidos en marcos de gobernanza más amplios. El NIST AI Risk Management Framework estructura la gestión del riesgo de IA como un proceso continuo que abarca gobierno, contextualización, medición y gestión a lo largo de todo el ciclo de vida del sistema. De forma complementaria, ISO/IEC 42001 define los requisitos de un sistema de gestión de IA, incluyendo políticas, evaluaciones de impacto, control de proveedores y supervisión continua.
Los procesos automatizados de MLOps y LLMOps (pipelines de datos, validaciones sistemáticas, despliegues controlados y monitorización permanente) son los mecanismos concretos que permiten que estos marcos de gobernanza pasen de la teoría a la práctica. Sin una base operativa sólida, la gobernanza de la IA queda reducida a documentación aspiracional; sin marcos de gobernanza claros, la industrialización técnica carece de criterios de calidad, responsabilidad y control del riesgo.
La adopción madura de la IA exige, por tanto, una convergencia real entre ingeniería, operaciones y gobernanza. La industrialización de la IA no consiste únicamente en escalar modelos, sino en construir sistemas confiables, auditables y sostenibles que puedan integrarse de forma responsable en procesos críticos de negocio. MLOps y LLMOps son marcos de buenas prácticas en evolución activa, no soluciones cerradas: si el problema de llevar IA a producción estuviera resuelto, no se observaría la persistencia de modelos que se degradan silenciosamente, generan costes no anticipados o fallan al escalar. Su valor es reducir la fricción y estructurar la gestión del riesgo, no eliminarlo.
Upskilling, reskilling y nuevos roles profesionales
El factor humano, cuello de botella de la IA
La proliferación de la IA está transformando el trabajo de forma más profunda de lo que sugieren los debates centrados únicamente en la automatización o sustitución de tareas. El principal reto para las organizaciones no es tecnológico, sino humano: disponer de las capacidades adecuadas para diseñar, desplegar, operar y gobernar sistemas de IA de manera sostenible. En este contexto, el talento deja de entenderse como un conjunto reducido de expertos y pasa a concebirse como una competencia organizativa distribuida.
Las conclusiones de esta sección se apoyan en un análisis empírico exhaustivo realizado por Management Solutions sobre un conjunto de 16 grandes organizaciones de Europa y Estados Unidos, basado en datos reales de mercado y evidencia organizativa.
Convergencia hacia un núcleo estable de roles de IA
A medida que la IA madura, las organizaciones convergen hacia un conjunto relativamente estable de competencias y capacidades profesionales. Aunque la nomenclatura varía entre sectores y empresas, las funciones que desempeñan estos perfiles comienzan a ser homogéneas. Sin embargo, los roles formales son menos que los skillsets subyacentes: en la práctica, un mismo profesional combina varias de estas capacidades, y las combinaciones más inusuales (quien domina a la vez LLMOps, regulación y prompt engineering, por ejemplo) son precisamente las más valiosas y escasas. Esta convergencia refleja una realidad operativa: el ciclo de vida de la IA (desde los datos hasta la producción y el control) requiere capacidades diferenciadas que no pueden concentrarse en un único tipo de profesional.
De forma sintética, estos roles pueden agruparse en tres grandes bloques (Fig. 6). En primer lugar, perfiles técnicos, responsables de diseñar modelos, construir infraestructuras de datos y llevar soluciones a producción. En segundo lugar, perfiles híbridos, que conectan capacidades técnicas con necesidades de negocio y aseguran que los sistemas de IA generen valor real y sean adoptados. Por último, perfiles de gobierno y control, encargados de gestionar riesgos, cumplimiento normativo, auditoría y uso responsable de la IA.
Esta estructura de competencias constituye la columna vertebral sobre la que se construyen las capacidades de IA de las organizaciones, independientemente del sector en el que operen.
Figura 6. Perfiles consolidados y emergentes en IA.
 |
Madurez desigual en la adopción de roles especializados
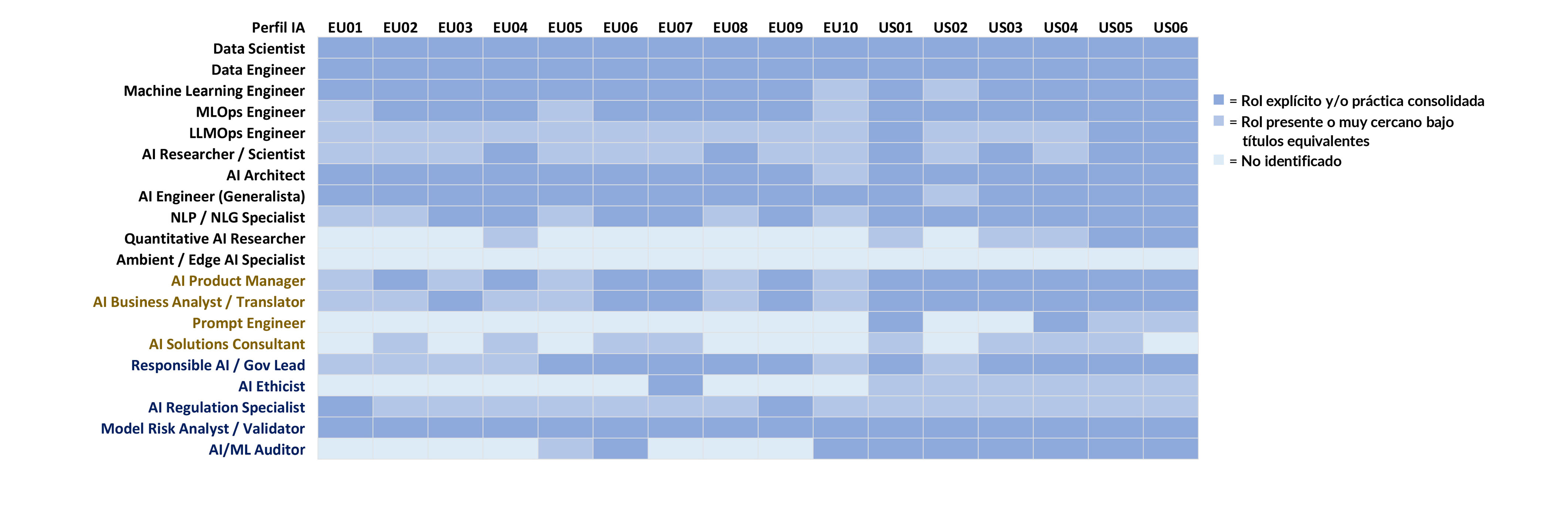
Aunque el núcleo básico de roles de IA está ampliamente implantado en organizaciones avanzadas (con heterogeneidad significativa), la adopción de perfiles emergentes o más especializados presenta una madurez muy desigual. Las diferencias no se observan tanto en la existencia de capacidades generales, como en la institucionalización de funciones avanzadas relacionadas con la operación de IA generativa y agéntica, la arquitectura a gran escala o el gobierno específico de estos sistemas.
Esta heterogeneidad es especialmente visible en roles emergentes vinculados a LLMOps, evaluación continua de modelos generativos, seguridad de prompts o gobierno de IA. En algunos casos, estas funciones existen como roles formales; en otros, se integran de manera informal en equipos más tradicionales, con resultados dispares en términos de control, escalabilidad y coste.
En el mapa de calor (Fig. 7) se ilustra que la diferencia entre organizaciones se manifiesta en qué roles han consolidado y con qué nivel de especialización y autonomía.
Figura 7. Mapa de calor de adopción de roles de IA.
 |
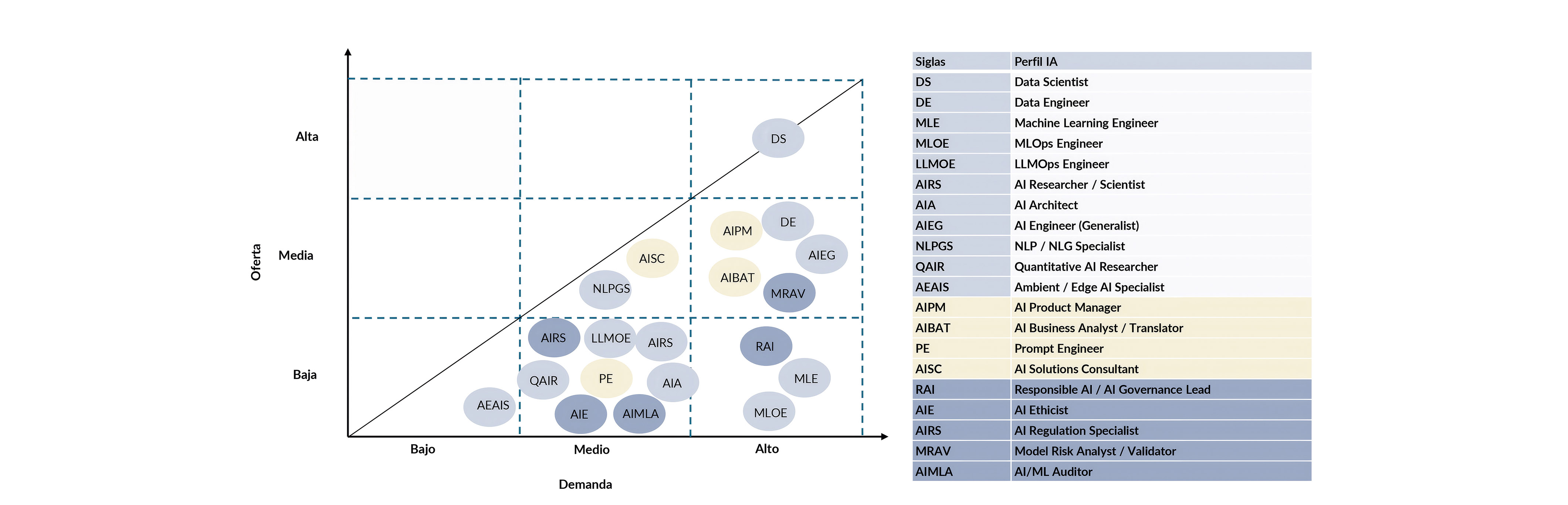
El cuello de botella real: desequilibrios oferta–demanda
El análisis de oferta y demanda (Fig. 8) muestra un desequilibrio estructural generalizado en el mercado de talento en IA. La demanda es elevada en prácticamente todos los perfiles analizados, mientras que la oferta resulta insuficiente de forma sistemática para absorberla. No se trata de una escasez puntual o concentrada, sino de un fenómeno transversal que afecta a la mayor parte del ecosistema profesional de la IA.
La única excepción parcial es el perfil de Data Scientist, que presenta una situación más cercana al equilibrio relativo. Este comportamiento responde a su mayor madurez histórica, a la existencia de trayectorias formativas consolidadas y a un mayor pool de profesionales con experiencia acumulada. Sin embargo, incluso en este caso, la presión de la demanda se mantiene elevada en posiciones senior o especializadas.
En el resto de perfiles, especialmente aquellos orientados a producción (Machine Learning Engineering, MLOps, LLMOps) y a funciones de gobierno, riesgo y control, la brecha entre demanda y oferta es persistente. La combinación de complejidad técnica, seniority requerida y creciente exigencia regulatoria limita la capacidad del mercado para generar talento al ritmo necesario. Como resultado, la contratación externa, por sí sola, no permite cerrar el gap, convirtiendo el upskilling y reskilling internos en una palanca estructural para escalar la IA con impacto y control.
Figura 8. Matriz oferta-demanda de perfiles de IA
 |
Implicaciones estratégicas
Las implicaciones de este análisis son claras. La estrategia de talento en IA no puede basarse exclusivamente en la captación de perfiles escasos en el mercado. El upskilling y reskilling internos se convierten en palancas estratégicas, especialmente para roles críticos donde la oferta externa es estructuralmente insuficiente.
Asimismo, los perfiles de operación y gobierno son tan determinantes como los de modelado o investigación. La ventaja competitiva no reside únicamente en desarrollar modelos avanzados, sino en integrarlos de forma segura, eficiente y conforme a regulación en los procesos reales de la organización.
IA y transformación sectorial (AI + X)
La IA como capa transversal
La IA ha dejado de ser una tecnología aplicada de forma incremental en sectores específicos para convertirse en una capa transversal de inteligencia que se integra simultáneamente en múltiples dominios económicos y sociales. Esta transición, ampliamente documentada por organismos internacionales, se caracteriza por el paso desde pilotos aislados hacia una adopción estructural que afecta a procesos completos, cadenas de valor y modelos operativos. No todo el avance responde a una lógica transversal: algunos de los desarrollos más significativos son impulsados por sectores específicos (la IA médica, la defensa o los servicios financieros regulados) donde la especificidad del dominio, la naturaleza de los datos o el marco regulatorio generan capacidades que difícilmente se transfieren a otros contextos sin adaptación sustancial.
Desde una perspectiva comparada, la evidencia muestra que las diferencias entre sectores ya no se explican por la mera presencia de IA, sino por la intensidad y profundidad de su integración. La OCDE clasifica los sectores según su «AI intensity» atendiendo a factores como la composición de tareas, la disponibilidad de datos y el capital humano, mostrando que incluso sectores tradicionalmente poco digitalizados están incrementando rápidamente su exposición a la IA. Esta adopción ocurre de forma paralela entre sectores, generando efectos de aceleración cruzada y aprendizaje intersectorial.
En términos macroeconómicos y laborales, el impacto es sistémico. El Fondo Monetario Internacional estima que alrededor del 40% del empleo global está expuesto a la IA, con porcentajes superiores en economías avanzadas, donde la complementariedad entre IA y trabajo cualificado es mayor. La Organización Internacional del Trabajo matiza que la IA generativa tiende a automatizar tareas concretas más que ocupaciones completas, reforzando la necesidad de adaptación organizativa y formación continua.
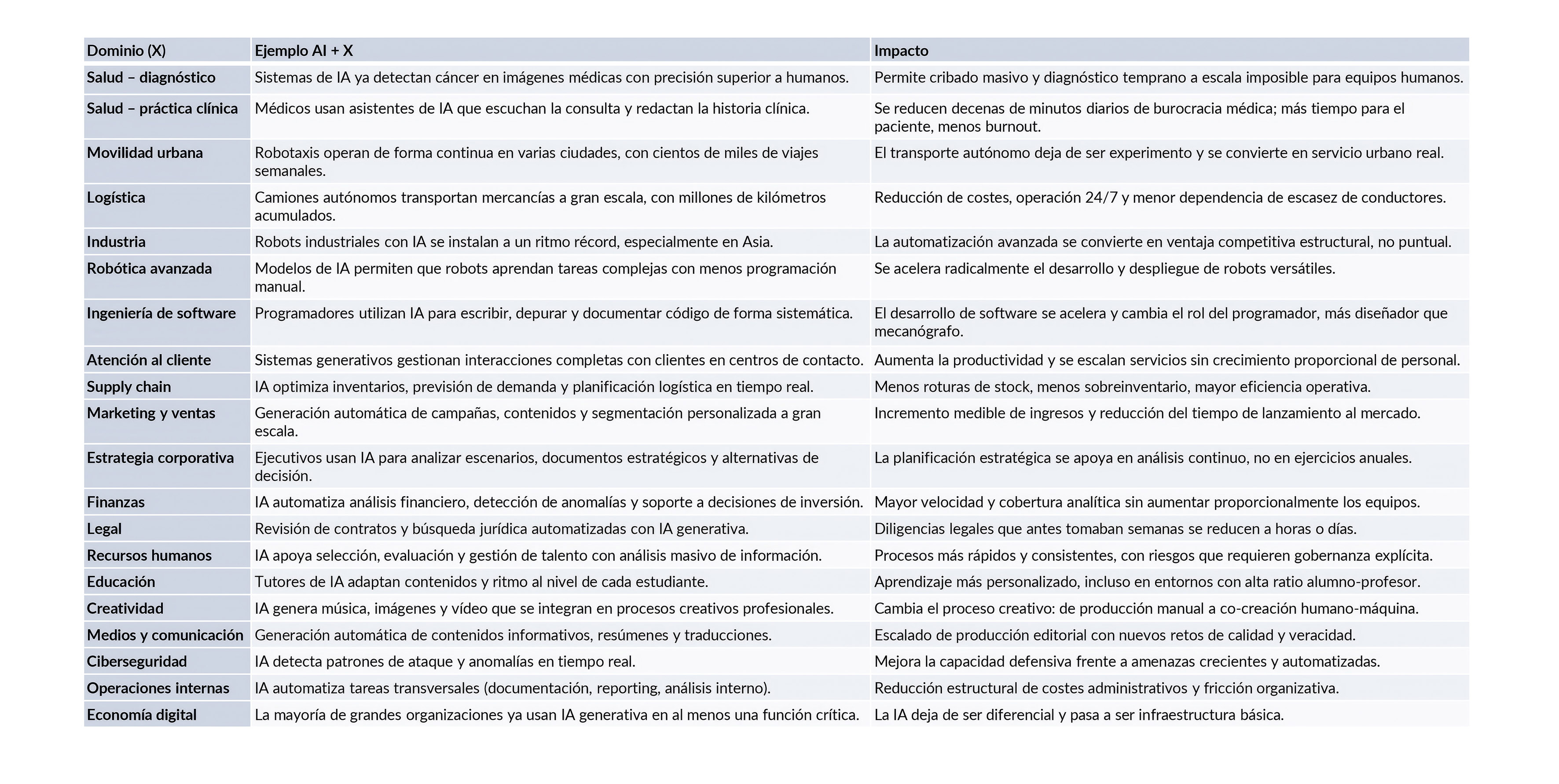
En este contexto, el concepto AI + X resulta útil para describir un patrón estructural: la IA se combina con dominios sectoriales específicos sin perder su carácter de tecnología de propósito general. No se trata de una suma de casos de uso independientes, sino de una integración simultánea y transversal, respaldada por evidencia empírica reciente. En esta sección se presentan algunos ejemplos ilustrativos, sin ánimo de exhaustividad (Fig. 9).
Salud (AI + Health): precisión clínica y escalabilidad
En el ámbito sanitario, la IA se está integrando en diagnóstico clínico, apoyo a la decisión médica, monitorización de pacientes y automatización administrativa. La Organización Mundial de la Salud documenta un crecimiento sostenido del uso de sistemas de IA en radiología, anatomía patológica y atención primaria, destacando tanto su potencial clínico como los riesgos asociados.
En múltiples estudios se demuestra que los sistemas de IA alcanzan niveles de precisión comparables o superiores a especialistas humanos en tareas como detección de cáncer en imágenes médicas o clasificación dermatológica. Estos resultados no implican sustitución directa, pero sí una ampliación significativa de la capacidad diagnóstica y de cribado a gran escala. Este avance, subraya la OMS, exige marcos sólidos de gobernanza, validación clínica y supervisión humana, dado su impacto directo en personas.
Educación (AI + Education): personalización a escala
En educación, la IA generativa está transformando la creación de contenidos, la evaluación y el acompañamiento al aprendizaje. UNESCO identifica el uso creciente de tutores adaptativos, generación automática de materiales didácticos y sistemas de evaluación formativa continua, con potencial para mejorar la personalización y reducir brechas educativas.
La educación es uno de los sectores donde la IA puede tener impactos estructurales a medio plazo, al permitir modelos de aprendizaje más flexibles y adaptativos. No obstante, estos beneficios dependen críticamente de políticas públicas y marcos institucionales que preserven la equidad, la integridad académica y el rol del profesorado.
Trabajo y empleo (AI + Work): reconfiguración de tareas
La IA está redefiniendo el trabajo de forma transversal, afectando a ocupaciones en prácticamente todos los sectores. El IMF estima que la exposición a la IA alcanza aproximadamente el 60% del empleo en economías avanzadas, frente a porcentajes menores en economías emergentes, reflejando diferencias en estructura productiva y capital humano.
La ILO, por su parte, concluye que la IA generativa tiene por ahora un mayor impacto sobre tareas cognitivas específicas que sobre empleos completos, lo que implica una reconfiguración del contenido del trabajo más que una sustitución masiva. Esta evidencia refuerza la necesidad de estrategias de upskilling y reskilling, como se ha analizado anteriormente.
Industria y operaciones (AI + Industry): productividad y eficiencia
En entornos industriales y operativos, la IA se aplica a mantenimiento predictivo, optimización de procesos, planificación y robótica avanzada. Muchas organizaciones han pasado ya de pruebas piloto a despliegues a escala, integrando la IA en procesos críticos de producción y logística. Ya hay evidencia sólida de mejoras significativas de eficiencia y reducción de fallos en sistemas industriales donde la IA se integra de forma sistemática, aunque los mayores beneficios se observan cuando la tecnología se acompaña de cambios organizativos y de procesos.
Finanzas y servicios intensivos en información (AI + Finance)
En sectores intensivos en información, como finanzas y servicios profesionales, la IA se utiliza para detección de fraude, gestión de riesgos, personalización de servicios y automatización documental. Se observa una expansión sostenida del uso de IA en estos ámbitos, con diferencias relevantes según el marco regulatorio y la capacidad organizativa.
La adopción de IA generativa en estos sectores se asocia a mejoras de productividad y a la aparición de nuevos modelos de servicio, aunque se advierte que los beneficios dependen de la calidad de los datos, la gobernanza y la integración en procesos existentes.
Creatividad y contenidos (AI + Creative): nuevos modelos culturales
La generación de texto, imagen, música y vídeo mediante IA está transformando industrias creativas y de medios. Se observa un crecimiento acelerado de estas aplicaciones y un aumento significativo de su uso comercial y cultural en los últimos años.
Este avance plantea debates regulatorios y económicos relevantes, especialmente en torno a propiedad intelectual y modelos de negocio, que están siendo abordados de forma desigual por distintos marcos normativos.
Síntesis: de sectores a infraestructura transversal
Más allá de los ejemplos sectoriales, la evidencia converge en un punto central: la transformación actual no reside en la adopción aislada de IA en sectores concretos, sino en su integración simultánea y transversal como infraestructura operativa y cognitiva. Los estudios coinciden en que la ventaja competitiva ya no se obtiene aplicando IA a funciones individuales, sino integrándola de forma coherente a lo largo de toda la cadena de valor. En este sentido, AI + X no describe ya una moda terminológica, sino un patrón estructural de transformación. Comprender esta lógica resulta esencial para anticipar impactos sectoriales, diseñar políticas públicas adecuadas y definir estrategias organizativas capaces de capturar el valor de la IA de manera sostenible.
Figura 9. Ejemplos representativos de AI + X, priorizando casos donde la IA ha pasado de piloto a uso operativo medible. Fuente: adaptado de Stanford (2025).
 |
IA en la vida personal y cotidiana
La inversión del paradigma: primero las personas, después las organizaciones
La IA generativa ha protagonizado una inversión radical del paradigma tecnológico tradicional. A diferencia de tecnologías empresariales anteriores (cloud computing, ERP, CRM) que nacieron en entornos corporativos y gradualmente se filtraron hacia el consumo personal, la IA generativa irrumpió primero en la vida cotidiana de las personas y solo después fue adoptada formalmente por las organizaciones.
Los datos son contundentes: se estima que ChatGPT alcanzó aproximadamente 900 millones de usuarios activos semanales a finales de 2025. Esta cifra coloca a la IA generativa entre las tecnologías de adopción más rápida de la historia, superando la velocidad de penetración de internet móvil, redes sociales o servicios de streaming.
Más revelador aún, la proporción de uso personal no solo precede, sino que supera sistemáticamente al uso profesional. En la Unión Europea, el 25,1% de la población utiliza herramientas de IA generativa para propósitos personales, frente al 15,1% que las emplea en contextos laborales y apenas el 9,4% en educación formal. En los países de la OCDE, más de un tercio de los individuos reportan uso regular de IA generativa, con los estudiantes liderando la adopción: tres cuartas partes de estudiantes mayores de 16 años utilizan estas herramientas, mientras que el 41,1% de los empleados las integra en su trabajo, frecuentemente de manera informal incluso antes de que sus organizaciones lo autoricen.
Esta secuencia temporal no es anecdótica: redefine la lógica de la transformación digital. Las organizaciones no están liderando la adopción de IA; están respondiendo a capacidades que sus empleados, clientes y proveedores ya poseen y utilizan extraoficialmente. El fenómeno del shadow AI (uso no autorizado de herramientas de IA en entornos corporativos) no es una anomalía transitoria, sino una consecuencia estructural de esta inversión: las personas adquirieron competencias cognitivas aumentadas en su vida personal que luego trasladaron espontáneamente a sus trabajos, creando exposiciones de riesgo que la mayoría de las empresas aún no controla.
Magnitud, distribución y fracturas: quién usa IA y para qué
La adopción de la IA en la vida personal abarca un espectro amplio de actividades. Los usos dominantes incluyen creación de contenido (textos, imágenes, música y vídeos), apoyo al aprendizaje y exploración conceptual, automatización de tareas rutinarias, acompañamiento conversacional y acceso a información: en Estados Unidos, el 10% de los adultos utiliza chatbots de IA para obtener noticias, introduciendo un nuevo vector de mediación informativa con implicaciones profundas para el debate público.
Sin embargo, esta democratización es radicalmente asimétrica. Las divisiones geográficas son extremas: en Noruega, el 56% de la población usa herramientas de IA generativa; en Dinamarca, el 48,4%; en Estonia, el 46,6%. En contraste, en Turquía la cifra cae al 17%; en Rumanía, al 17,8%. Incluso dentro de economías desarrolladas, las diferencias son sustanciales: Alemania se sitúa en el 32%, Francia en el 37%, España en el 38%, mientras Italia permanece por debajo del 20%.
La brecha generacional es aún más pronunciada. La diferencia en adopción entre los grupos de edad más jóvenes y los de mayor edad alcanza los 53,6 puntos porcentuales, convirtiéndose en el factor de segmentación más determinante, por encima de la educación (21 puntos porcentuales de brecha) o el nivel de ingresos (21 puntos). Mientras que el 75% de los estudiantes utiliza IA generativa regularmente, solo el 12,5% de las personas jubiladas o económicamente inactivas reporta haberla usado. La brecha de género, en cambio, es comparativamente menor: 4,2 puntos porcentuales.
La paradoja de la adopción masiva
A nivel global, el 66% de la población cree que los productos y servicios basados en IA impactarán significativamente en su vida diaria en los próximos tres a cinco años, un incremento de seis puntos porcentuales desde 2022. Sin embargo, este reconocimiento del impacto inminente coexiste con una ambivalencia creciente.
El público general muestra un nivel elevado de preocupación: en Estados Unidos, el 51% de los adultos manifiesta estar más preocupado que entusiasmado por el aumento del uso de IA en la vida cotidiana, frente a solo el 11% que expresa mayor entusiasmo. Entre expertos en IA, la relación se invierte: el 47% está más emocionado que preocupado, y solo el 15% más preocupado. Esta divergencia de 40 puntos porcentuales entre expertos y público refleja no solo diferencias en conocimiento técnico, sino percepciones estructuralmente distintas sobre el balance riesgo-beneficio.
La familiaridad con la IA no conduce automáticamente a la confianza. Aunque el uso personal correlaciona positivamente con la percepción de la IA como oportunidad, también aumenta la conciencia de sus riesgos. La confianza en que las empresas de IA protegen adecuadamente los datos personales oscila entre el 50% en 2023 y el 47% en 2024. Simultáneamente, disminuyó la proporción de personas que creen que los sistemas de IA son imparciales y libres de discriminación.
El contexto de uso resulta absolutamente crítico. Investigaciones en el Reino Unido muestran oscilaciones de hasta 110 puntos porcentuales en la aceptación pública según el caso de uso específico: desde un balance neto de +53% de comodidad con el uso de IA para analizar datos de tráfico en tiempo real y mejorar flujos viales, hasta un balance de –57% frente al uso de IA para analizar preferencias políticas y dirigir publicidad personalizada.
Existe, sin embargo, un consenso transversal entre expertos y público general: ambos grupos desean mayor control sobre cómo se utiliza la IA en sus vidas (55% del público y 57% de los expertos), y ambos sienten no disponer actualmente de ese control (menos del 25% en ambos casos). Esta brecha entre demanda de agencia y percepción de impotencia constituye uno de los desafíos más urgentes de gobernanza democrática de la IA.
Desigualdad de acceso y riesgo de exclusión
La asimetría en la adopción de IA en la vida personal no es una brecha digital convencional. No se trata meramente de acceso a infraestructura tecnológica (conexión a internet, dispositivos), sino de acceso diferenciado a capacidad intelectual aumentada. Quienes integran la IA como herramienta cognitiva cotidiana adquieren ventajas acumulativas en aprendizaje, productividad, creatividad y acceso a información. Quienes no lo hacen enfrentan un rezago estructural creciente.
Los grupos digitalmente desconectados perciben la IA de forma marcadamente negativa: el 51% anticipa un impacto personal negativo, frente a solo el 17% que espera beneficios. Esta percepción no es irracional: refleja la intuición de que la transformación en curso puede redistribuir las oportunidades de forma profundamente desigual.
IA, sostenibilidad e impacto social
La sostenibilidad entra en la era algorítmica
La transición sostenible ha dejado de ser exclusivamente una cuestión de infraestructuras físicas (nuevas plantas renovables, redes eléctricas o electrificación del transporte) para convertirse también en un desafío de coordinación sistémica. Los sistemas energéticos actuales combinan generación distribuida, intermitencia renovable, almacenamiento, mercados dinámicos y demanda flexible. Esta complejidad no puede gestionarse únicamente con reglas estáticas o planificación lineal.
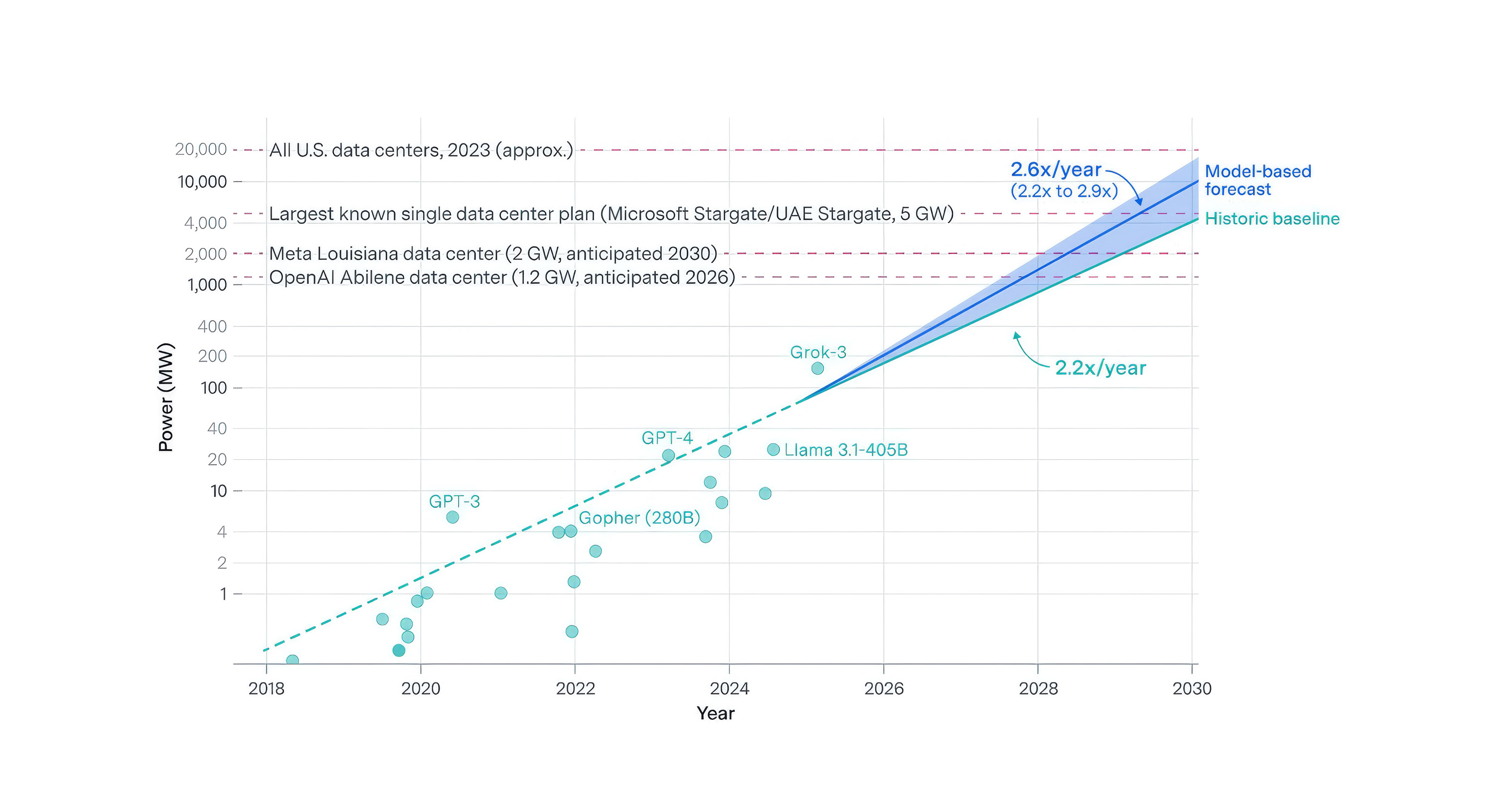
En este contexto, la IA emerge como infraestructura cognitiva capaz de modelizar interdependencias, simular escenarios y optimizar decisiones en tiempo real. La electrificación acelerada y el crecimiento estructural de la demanda eléctrica están reconfigurando las necesidades de capacidad, flexibilidad y planificación de redes en los próximos años: en 2024, los centros de datos consumieron un 1,5% de la electricidad global, la potencia requerida para entrenar los modelos de frontera está creciendo a un ritmo de 2,2x a 2,9x por año (Fig. 10), y las mayores ejecuciones ya superan los 100 MW de potencia instantánea. La sostenibilidad entra así en una fase en la que la capacidad computacional se convierte en parte integrante de la arquitectura energética y climática.
El cambio es conceptual: de decisiones basadas en promedios históricos a decisiones fundamentadas en simulaciones dinámicas y análisis probabilísticos de alta resolución. La IA no sustituye a la ingeniería ni a la física, pero amplifica la capacidad de anticipación y coordinación en sistemas con múltiples variables y restricciones simultáneas.
Figura 10. Crecimiento de la demanda energética de la IA de frontera. Fuente: Epoch (2025b).
 |
Optimizar el planeta: eficiencia, resiliencia y adaptación
En términos operativos, la IA está actuando como acelerador de la transición. En redes eléctricas, los modelos predictivos permiten anticipar picos de demanda, optimizar despacho, reducir congestiones y mejorar la integración de renovables variables. Sin IA, la integración óptima de renovables y la gestión en tiempo real tendría mayor incertidumbre. En un entorno donde la electricidad adquiere un papel central en la descarbonización, la eficiencia operativa deja de ser marginal y se convierte en condición estructural.
La relación entre energía e IA es además bidireccional: la IA puede mejorar significativamente la eficiencia energética, la planificación de redes y la gestión de sistemas complejos, y reducir emisiones del orden de 1.400 Mt CO₂eq anuales hacia 2035 en escenarios de adopción amplia ; sin embargo, ese potencial de reducción coexiste con un incremento estructural del consumo energético de la propia infraestructura de IA que, en ausencia de una transición paralela hacia energías limpias, puede resultar en un balance neto neutro o negativo en términos de emisiones. La pregunta estratégicamente relevante no es si la IA puede contribuir a la descarbonización —puede hacerlo—, sino bajo qué condiciones energéticas y de gobernanza ese potencial se materializa sin ser consumido por su propia huella infraestructural.
Más allá del sistema eléctrico, la IA mejora la resiliencia frente a riesgos físicos crecientes. La modelización climática apoyada en aprendizaje automático incrementa la granularidad espacial y temporal de las predicciones, facilitando decisiones en planificación urbana, seguros e infraestructuras críticas. En agricultura y gestión hídrica, la optimización basada en datos reduce desperdicios y ajusta insumos bajo restricciones ambientales.
Estos desarrollos se insertan en una agenda global más amplia. El progreso hacia los Objetivos de Desarrollo Sostenible avanza en un contexto de tensiones energéticas, climáticas y demográficas. En ese escenario, la IA puede actuar como catalizador transversal: no como sustituto de políticas públicas, sino como herramienta que mejora eficiencia, reduce fricciones y permite asignaciones más precisas de recursos escasos.
El coste oculto: energía, materiales y concentración infraestructural
La misma infraestructura digital que habilita estas mejoras genera nuevas presiones. El crecimiento de data centers y cargas computacionales asociadas a IA está contribuyendo al aumento de la demanda eléctrica en determinadas economías avanzadas:
- La IEA proyecta que el consumo eléctrico de data centers globales se multiplicará para 2030, alcanzando 945 TWh/año, equivalente al consumo de electricidad de Japón hoy, con la IA como principal motor de esa expansión.
- Las mayores ejecuciones individuales de entrenamiento de modelos de frontera podrían requerir entre 4 y 16 GW de potencia hacia 2030, equivalente a la generación de varias centrales nucleares y al consumo eléctrico de millones de hogares.
- La potencia necesaria para entrenar modelos de frontera ha venido creciendo más de 2x por año, impulsada por un crecimiento del cómputo de 4–5x anual, parcialmente compensado por mejoras de eficiencia energética del hardware (ca. 40% anual en GPUs líderes).
Por tanto, el despliegue masivo de modelos avanzados puede convertirse en un factor estructural de crecimiento del consumo eléctrico si no se acompaña de mejoras en eficiencia y planificación energética.
La sostenibilidad de la IA no puede evaluarse únicamente por los beneficios que produce, sino también por los recursos que consume: en escenarios base, las emisiones de CO₂ por electricidad de data centers podrían alcanzar 300–320 Mt CO₂ al año hacia 2030 si la electricidad adicional sigue dependiendo en buena parte de combustibles fósiles. El entrenamiento y el despliegue de modelos a gran escala requieren energía, agua para refrigeración (en algunas regiones, en competencia directa con uso agrícola o doméstico) y hardware intensivo en materiales críticos. Además, la localización geográfica de centros de datos introduce asimetrías: la intensidad de carbono de la electricidad varía sustancialmente entre regiones, lo que implica huellas ambientales diferenciadas para el mismo servicio digital.
Esta dimensión infraestructural añade una capa geopolítica. La concentración de capacidad computacional en determinados países o regiones reconfigura dependencias estratégicas y acceso a tecnología. La IA no es solo una herramienta ambiental; es también un nodo crítico en el mapa energético y tecnológico global.
La cuestión no es si la IA «compensa» su huella, sino cómo se diseña y despliega para maximizar eficiencia energética por unidad de capacidad cognitiva generada. La sostenibilidad de la IA se convierte así en un problema de arquitectura y gobernanza.
Sostenibilidad sin inclusión no es sostenible
La dimensión ambiental no agota el análisis. Conviene distinguir entre la transición energética socialmente justa (vinculada al cambio del modelo productivo y energético) y la transición justa asociada al propio despliegue de la IA. Esta última introduce efectos distributivos específicos. La capacidad de integrar tecnologías avanzadas depende de capital humano, infraestructura digital y calidad institucional. Las economías con mayor densidad tecnológica tienden a capturar antes los beneficios de productividad y eficiencia, ampliando potencialmente brechas con regiones menos preparadas.
Desde la perspectiva del desarrollo humano, la tecnología puede expandir capacidades (educación, acceso a servicios, participación económica, etc.) o consolidar exclusiones existentes, dependiendo del contexto de adopción y del grado de democratización en el acceso a sus herramientas. La extensión de capacidades digitales a pymes, emprendedores y colectivos con menor capital tecnológico constituye un mecanismo relevante para acompasar creación y ajuste. En el ámbito laboral, la convergencia entre transición verde y automatización inteligente puede acelerar procesos de reasignación sectorial y transformación de competencias, con una secuencia temporal en la que los efectos de desplazamiento pueden preceder a la creación de nuevas oportunidades. La gestión de ese desfase exige planificación estratégica, políticas activas de capacitación y mecanismos que faciliten la difusión amplia de las ganancias de productividad.
Desde una perspectiva estructural, la sostenibilidad ambiental requiere una transición energética socialmente justa, que evite concentrar los costes del cambio en determinados territorios, sectores o colectivos. Este desafío es conceptualmente independiente del uso de la IA. De forma paralela, el despliegue de la IA plantea su propia transición justa: los beneficios de productividad y eficiencia tienden a materializarse de manera desigual y con un desfase temporal respecto a los impactos negativos iniciales, especialmente en el empleo y en determinadas cualificaciones. Por ello, la IA aplicada a la sostenibilidad debe evaluarse no solo por su impacto agregado, sino también por la distribución efectiva de sus beneficios y por las estrategias públicas y privadas que permitan ampliar su acceso y mitigar los costes sociales del ajuste.
IA sostenible por diseño: de la ambición a la disciplina
La convergencia de estas dimensiones (optimización sistémica, presión infraestructural y efectos distributivos) obliga a desplazar el debate desde principios generales hacia prácticas verificables. Una IA alineada con objetivos de sostenibilidad requiere métricas explícitas de consumo energético y emisiones asociadas, transparencia sobre arquitectura y localización de despliegue, y evaluación de impactos sociales en decisiones automatizadas.
El marco de los ODS refuerza esta necesidad de coherencia estructural entre tecnología y desarrollo sostenible. A su vez, la interrelación entre energía y digitalización exige integrar variables energéticas en la planificación tecnológica corporativa y pública.
En síntesis, la IA ocupa una posición ambivalente en la transición sostenible: puede habilitar reducciones de emisiones del orden de gigatoneladas y, al mismo tiempo el entrenamiento de sus modelos más avanzados podría alcanzar escalas de 4–16 GW por ejecución individual hacia 2030, situando la IA en la misma magnitud energética que grandes infraestructuras industriales.
La IA es, simultáneamente, acelerador de eficiencia sistémica, nueva carga infraestructural y fuerza distributiva con efectos sociales diferenciados. La cuestión no es si la IA formará parte de la transición sostenible, sino en qué condiciones energéticas y distributivas lo hará.
Ética y filosofía de la IA
Un problema abierto tras más de 200 marcos
La OIT ha catalogado 245 marcos, códigos y recomendaciones de ética de la IA emitidos desde 2017 por gobiernos, organismos internacionales, empresas y sociedad civil ; un metaanálisis académico previo había identificado al menos 17 principios recurrentes en 200 de ellos: transparencia, equidad, rendición de cuentas, privacidad…, existe un consenso normativo de base. Y, sin embargo, los problemas éticos asociados a la IA no han remitido con la proliferación de estos marcos, sino que han crecido en complejidad, y han emergido preguntas para las que ninguno de ellos ofrecía categorías previas.
La brecha entre la formulación de principios y su traducción a decisiones concretas no es un problema técnico pendiente de resolver: es el problema central de la gobernanza de la IA.
Del principio a la acción: cómo operativizar la ética de la IA
La distancia entre un documento de valores y el comportamiento real de un sistema de IA es donde reside el riesgo operativo. Este fenómeno, conocido como «ethics washing», no siempre responde a una actitud deliberada: con frecuencia refleja la dificultad genuina de traducir un principio abstracto («el sistema debe ser equitativo») en un criterio de diseño, un procedimiento de auditoría o una línea de responsabilidad organizativa. Abordar esta brecha exige una transformación de la aproximación a la ética, que pasa de ser declarativa a operativa.
Un modelo bien documentado y ampliamente citado de operativización en el sector financiero es De Volksbank, banco neerlandés cuya gobernanza de ética de IA ha sido analizada en detalle. Su estructura incluye un área de AI Ethics integrada en la función de Compliance, con perfiles de formación filosófica y técnica, que evalúa cada sistema de IA de forma individual antes de su despliegue: análisis de impacto ético, examen de sesgos, trazabilidad de decisiones y canales formalizados de escalado. El caso ilustra que la operativización efectiva no reside en el alcance de los principios enunciados, sino en la solidez de los procesos, roles y puntos de decisión que los materializan.
Sintetizando el estado del arte, un marco de ética de IA operativo en una gran organización incorpora habitualmente seis componentes:
1. Estructura de gobernanza: definición de quién decide, quién revisa y qué líneas de defensa existen, con documentación explícita de responsabilidades.
2. Evaluación de impacto por sistema: análisis específico para cada caso de uso, proporcional al nivel de autonomía del sistema y a las consecuencias de las decisiones delegadas en él.
3. Gestión continua de sesgos: mecanismos de detección y corrección que operan de forma permanente, no como auditorías puntuales.
4. Transparencia y explicabilidad diferenciada por audiencia: los requerimientos informativos del regulador, del cliente y del empleado afectado por una decisión automatizada son sustancialmente distintos.
5. Mecanismos de escalado y denuncia: canales accesibles y protegidos para señalar comportamientos inesperados del sistema.
6. Revisión periódica del propio marco: las actualizaciones de los modelos pueden alterar el perfil de riesgo de los usos ya desplegados, lo que exige reevaluación continua, no solo en el momento del despliegue inicial.
Un referente reciente de operativización actúa a un nivel más profundo: no en la capa de despliegue organizativo, sino en el propio entrenamiento del modelo. La Constitution publicada por Anthropic en enero de 2026 es el primer documento público de un laboratorio de frontera que codifica valores directamente en el proceso de entrenamiento, con una jerarquía explícita y razonada entre seguridad, ética, cumplimiento y utilidad. El cambio conceptual subyacente es significativo: en lugar de imponer reglas de comportamiento desde fuera, se busca que el sistema internalice el razonamiento detrás de cada principio, de forma que pueda generalizar ese juicio a situaciones no anticipadas.
El avance de la función ética hacia la operativización enfrenta, no obstante, un límite conceptual que los marcos actuales no resuelven: asumen implícitamente que existe claridad sobre qué tipo de entidad se está gobernando.
¿Qué estamos creando? La pregunta que los marcos no responden
Los marcos regulatorios vigentes, incluido el AI Act de la Unión Europea, clasifican los sistemas de IA por nivel de riesgo y dominio de aplicación. Esta clasificación es operativamente útil y proporciona cierta cobertura ética (en el sentido de proteger contra el potencial abuso de la IA), pero no distingue entre los diferentes tipos de relación que un sistema establece con el ser humano. Un sistema de scoring crediticio, un asistente conversacional y un agente autónomo que negocia contratos en nombre de una organización pueden coincidir en su categoría de riesgo regulatorio y operar, sin embargo, sobre bases éticas fundamentalmente distintas. Un sistema que adapta su comportamiento al interlocutor, mantiene coherencia a lo largo del tiempo y produce respuestas contextualmente indistinguibles de las de una persona con comprensión genuina, plantea preguntas que el cumplimiento normativo convencional no está diseñado para absorber.
Estas preguntas son de cuatro tipos, todos ellos accionables para las organizaciones que despliegan sistemas de IA:
- Ontología: ¿qué clase de entidad es este sistema, y qué categorías son pertinentes para describirlo y gobernarlo?
- Epistemología: ¿cómo verifica el sistema lo que afirma, y cómo puede el ser humano validar la fiabilidad de lo que produce?
- Teoría de la mente: ¿existe algún tipo de experiencia interna asociada al funcionamiento del sistema (por rudimentaria que sea) y qué implicaciones tendría eso para quienes lo diseñan y despliegan?
- Ética aplicada: ¿qué obligaciones genera el sistema para la organización que lo utiliza, más allá de lo que la regulación vigente exige explícitamente?
No se trata de preguntas especulativas. En enero de 2026, Anthropic reconoció públicamente que su modelo Claude «puede poseer alguna forma de consciencia o estatus moral», convirtiéndose en el primer laboratorio de frontera en hacer pública esta afirmación. La importancia de este reconocimiento no reside solo en lo que afirma, sino en lo que revela: que una empresa de primer nivel admite no poder responder con certeza a la pregunta de qué ha creado.
Todas las decisiones sobre cómo usar, auditar y regular un sistema de IA incorporan implícitamente una respuesta a esa pregunta. En la mayoría de organizaciones, esa respuesta se produce por defecto, sin deliberación explícita.
Cuatro fracturas: preguntas sin respuesta
La expansión de la IA no solo amplifica los dilemas éticos conocidos: genera fracturas conceptuales para las que los marcos jurídicos y éticos actuales no disponen de respuesta estructurada.
La primera es la crisis epistémica de la verificación. AlphaFold ha predicho la estructura de más de 200 millones de proteínas, y más de tres millones de investigadores en 190 países las utilizan como base de su trabajo. Una parte significativa de esas estructuras no puede verificarse experimentalmente con los métodos científicos convencionales, y sin embargo se emplean para diseñar fármacos y orientar decisiones clínicas. La cuestión de fondo no es si el sistema funciona (lo hace con un nivel de precisión sin precedentes), sino qué protocolos éticos y regulatorios corresponden a un escenario donde el conocimiento científicamente operativo se vuelve computacionalmente inaccesible para la verificación humana.
La segunda es la asimetría de responsabilidad en daños emergentes. Los marcos éticos y jurídicos heredados asumen actores identificables con intenciones discernibles. Los sistemas de IA producen daños sin intención deliberada directa y con causalidad distribuida entre múltiples actores (diseñadores, entrenadores, desplegadores y usuarios) configurando lo que la literatura denomina el ‘many hands problem’: situaciones en las que la responsabilidad moral y jurídica se diluye estructuralmente al fragmentarse la cadena causal. Los marcos de responsabilidad civil y los regímenes de cumplimiento normativo actuales no disponen de respuesta estructurada para este tipo de causalidad difusa.
La tercera es la representación de futuros no nacidos. Los sistemas de IA se entrenan sobre datos históricos. Sus sesgos son los del pasado humano, amplificados a escala. Ningún marco de ética de IA incorpora hoy mecanismos que representen los intereses de las generaciones que aún no han nacido, y por tanto no han producido datos, y que, sin embargo, vivirán con las consecuencias de los sistemas diseñados en el presente. Las implicaciones son directas para aplicaciones de largo alcance temporal, desde la planificación urbana hasta los modelos de riesgo climático.
La cuarta es el libre albedrío como riesgo sistémico. Una proporción creciente de decisiones individuales y organizacionales se toma, de facto, mediada por sistemas de IA cuya oferta está altamente concentrada: tres proveedores acumulan el 88% del gasto empresarial global en modelos de lenguaje, y el mercado de infraestructura cloud subyacente presenta una concentración similar. Esta estructura implica que un sesgo introducido de forma deliberada o accidental en uno de esos modelos no afecta a decisiones individuales, sino a millones de procesos simultáneos en organizaciones, sectores y países distintos. La diversidad cognitiva de una sociedad (i.e., su capacidad de llegar a conclusiones diferentes por caminos distintos) depende, en parte, de que los sistemas que median su pensamiento no sean homogéneos ni oligopólicos.
Estas cuatro fracturas no constituyen argumentos contra la adopción de la IA, sino el territorio conceptual que las organizaciones que gestionan esta adopción con seriedad han de aprender a habitar. Su relevancia no disminuye por no estar recogidas en los marcos regulatorios vigentes; al contrario, es precisamente esa ausencia la que las convierte en los riesgos con menor visibilidad y mayor potencial de daño.
Índice de la publicación

Introducción

Resumen ejecutivo

La explosión tecnológica de la IA


Gobierno de la IA e impacto en personas

Fronteras de la IA

Caso práctico: GenMS™ Sybil

Conclusión

Referencias y glosario