Tendências em Inteligência Artificial
Riscos, Regulação e Segurança da IA
Vídeo: TENDENCIAS EM IA
Índice da publicação
Download Documento
Acesso ao GenMS™ Sybil
A IA generativa e os sistemas agênticos oferecem recursos transformadores, mas introduzem riscos estruturais que não são mais hipotéticos: eles estão se materializando na produção. A Declaração de Bletchley advertiu explicitamente sobre os impactos potencialmente "catastróficos" da IA, e a experiência acumulada confirma que a lista de riscos é longa e diversificada. Esta seção analisa os riscos da IA, as estruturas regulatórias e a governança da IA, a batalha entre a IA defensiva e adversária na segurança cibernética e as tensões abertas na privacidade e na propriedade intelectual.
Riscos da IA
A IA não cria riscos: ela os amplifica
A adoção da IA não introduz, com algumas exceções, riscos substancialmente novos, mas amplia drasticamente os riscos existentes: operacionais, de modelo, tecnológicos, de fornecedores, jurídicos, de reputação, de compliance, estratégicos, sociais... A diferença não está na natureza do risco, mas em sua velocidade de propagação, escala de impacto e dificuldade de contenção.
Com exceção de algumas categorias emergentes (como a geração de conteúdo tóxico, certas formas de manipulação cognitiva por meio de deepfakes ou ataques de prompt injection), a maioria dos riscos associados à IA são versões aceleradas, automatizadas e massivas de problemas conhecidos. Uma tendência algorítmica é, em essência, uma tendência humana sistematizada e replicada milhões de vezes. Um vazamento de informações por meio do uso indevido de um chatbot é, no fim das contas, um vazamento de informações.
Quatro dimensões interconectadas
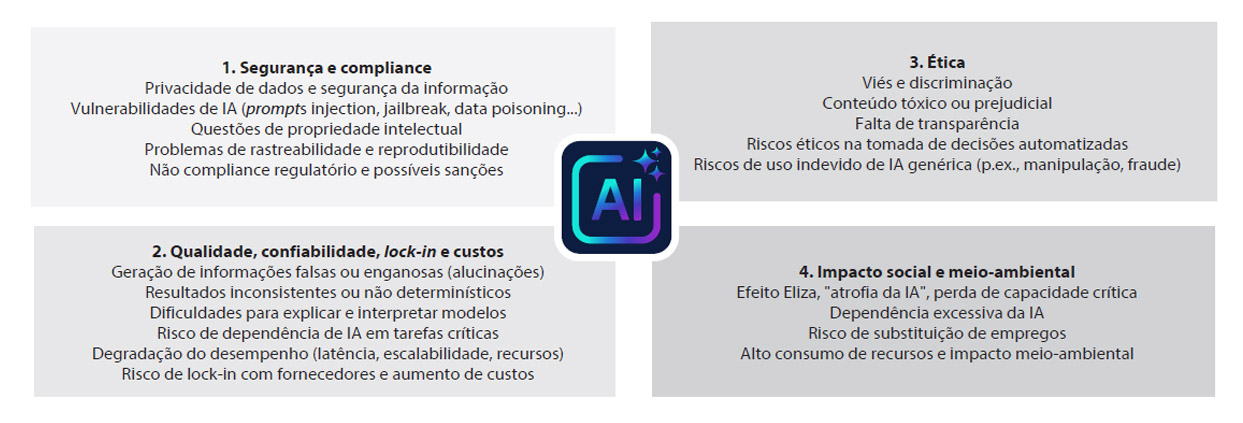
Na prática, esses riscos se materializam em quatro grandes dimensões (Fig. 3):
1. Segurança e compliance
A IA introduz novas superfícies de ataque e complica a compliance regulatório. A privacidade e a segurança das informações enfrentam ameaças específicas: vazamentos não intencionais de dados confidenciais, vulnerabilidades técnicas emergentes, como prompt injection (instruções maliciosas incorporadas em entradas que "enganam" o modelo para que ele ignore as restrições) ou jailbreaks (técnicas para contornar os controles de segurança) e exposição acidental de informações confidenciais quando os profissionais usam ferramentas não seguras.
A propriedade intelectual torna-se ambígua: a quem pertence o código gerado pela IA, o que acontece quando um modelo reproduz fragmentos protegidos por direitos autorais? Como exemplo, o New York Times está em um litígio aberto com a OpenAI/Microsoft por usar conteúdo protegido por direitos autorais sem licença, entre muitos outros processos em andamento.
A rastreabilidade e a reprodutibilidade são prejudicadas quando decisões críticas dependem de modelos que evoluem continuamente por meio de retreinamento automático, dificultando a reconstrução exata de qual versão do sistema produziu qual resultado e em qual momento.
E o não compliance agora tem consequências financeiras diretas e visíveis: a Lei Europeia de IA prevê multas de até 35 milhões de euros ou 7% do faturamento global anual, tornando o compliance com a IA um risco material da mais alta ordem, maior até do que a proteção de dados.
2. Qualidade, confiabilidade, lock-in e custos
Conforme mencionado acima, a IA generativa produz resultados plausíveis, não necessariamente corretos. As alucinações (geração de informações falsas apresentadas com confiança) não são erros ocasionais, mas um comportamento intrínseco ao projeto real dos modelos. O comportamento não determinístico significa que a mesma entrada pode produzir saídas diferentes no mesmo modelo, o que complica a validação, a auditoria e a certificação de processos críticos.
O desvio silencioso do modelo representa um dos riscos mais insidiosos: um modelo que funciona bem pode se degradar em um curto espaço de tempo porque a distribuição dos dados mudou, sem que existam mecanismos de monitoramento que gerem alertas antecipados. Um modelo pode continuar a operar com uma aparência de normalidade até que alguém detecte manualmente anomalias nos resultados.
A dependência excessiva da IA em tarefas críticas cria fragilidade operacional: se o sistema de IA falhar, travar ou se tornar proibitivamente caro, a organização poderá continuar operando? Existem procedimentos humanos de contingência? E a perda do controle humano efetivo ocorre quando as decisões são delegadas a sistemas cujo raciocínio interno é opaco até mesmo para aqueles que os desenvolvem e operam.
Além disso, as organizações criam dependências estruturais em alguns poucos provedores de modelos (OpenAI, Anthropic, Google) e infraestrutura (AWS, Azure, GCP). Mudanças nos preços, nos termos de serviço ou interrupções operacionais podem prejudicar processos essenciais simultaneamente. A migração entre ecossistemas envolve reescrever integrações, retreinar workflows, recertificar o compliance e assumir custos proibitivos, o que nem sempre é viável, a diversificação de fornecedores, embora dispendiosa, é a resposta estrutural a este risco.
Além dos riscos acima, há uma dimensão econômica que os frameworks de gestão tradicionais subestimam. Os custos unitários de inferência vêm caindo estruturalmente (aproximadamente 10 vezes a cada 12 meses), mas essa queda não protege contra o crescimento exponencial do volume: os sistemas agênticos têm estruturas de custo com escalabilidade não linear: cada agente multiplica as chamadas para modelos e ferramentas e, sem monitoramento de tokens em tempo real e limites de gastos explícitos desde o desenho, um protótipo viável pode se tornar um sistema insustentável antes que alguém perceba. Soma-se a isso a incerteza quanto ao retorno sobre o investimento: a questão de saber se os gastos massivos com IA gerarão o valor esperado ainda não está resolvida, e muitas organizações avançam impulsionadas pela pressão da concorrência em vez de um caso comercial sólido. O Gartner sintetiza os dois riscos em uma previsão: mais de 40% dos projetos de agentic serão cancelados até 2027 devido ao aumento dos custos, ao valor comercial pouco claro e aos controles de risco inadequados. O lock-in agrava o problema estruturalmente: a dependência de um único fornecedor elimina a capacidade de migrar para arquiteturas mais eficientes quando elas estiverem disponíveis.
3. Ética e tomada de decisão automatizada
Os vieses algorítmicos amplificam os vieses presentes nos dados históricos: se um modelo de recrutamento for treinado com dados de uma organização historicamente tendenciosa em relação a determinados perfis, o modelo sistematizará e aumentará esse viés. A falta de transparência e as dificuldades de explicação complicam o compliance com os requisitos regulatórios de que as decisões automatizadas devem ser compreensíveis e justificáveis, especialmente quando afetam os direitos fundamentais.
As decisões automatizadas com impacto humano direto (aprovação de crédito, diagnósticos médicos, avaliação de risco criminal, seleção de candidatos) levantam questões de responsabilidade: quem é responsável quando o modelo comete um erro com consequências graves: o fornecedor do modelo básico, a equipe que o personalizou, o usuário que escreveu o prompt, o comitê que aprovou sua implantação? A cadeia de responsabilidade torna-se complexa, criando lacunas de responsabilidade que nem a regulação nem a prática resolveram completamente.
4. Impacto social e organizacional
A transformação do trabalho não é mais especulativa: as tarefas manuais e cognitivas de rotina enfrentam uma automação acelerada, e as organizações precisam gerenciar as transições de trabalho, os programas de requalificação e as crescentes expectativas regulatórias e sociais sobre a responsabilidade corporativa.
A dependência cognitiva e a erosão de recursos essenciais representam um grande risco: se toda uma geração de profissionais aprender a trabalhar exclusivamente com IA como intermediária, eles manterão a intuição e o conhecimento suficientes para avaliar criticamente os resultados? O que acontecerá quando a IA não estiver disponível? E a pressão sobre os recursos e a pegada ambiental não é trivial: o treinamento de modelos avançados consome energia equivalente a milhares de residências durante meses, e a inferência em escala massiva levanta questões sobre a sustentabilidade de longo prazo.
Fig. 3. Alguns riscos da IA generativa.
 |
Amplificação não linear
A IA introduz um fenômeno fundamental na gestão de riscos: a amplificação não linear. Uma pequena falha (um viés de dados, um prompt mal projetado, uma configuração incorreta de permissão) pode aumentar em minutos e afetar simultaneamente os processos, os clientes, os órgãos reguladores e a reputação. Quanto maior for a autonomia e a integração da IA nos processos essenciais, maior será o raio de impacto da falha, o que exige a concepção, desde o início, de mecanismos de contenção proporcionais a essa escala.
Um exemplo concreto: um modelo de atendimento ao cliente que, após uma pequena alteração no prompt do sistema, começa a revelar informações confidenciais de outros clientes em "apenas" 0,01% das conversas, o que é quase indetectável nos testes. Em um sistema que lida com 100.000 interações por dia, isso significa 10 vazamentos por dia antes que o padrão seja detectado. Quando o problema é identificado, centenas de incidentes já ocorreram, cada um com implicações regulatórias, contratuais e de reputação.
IA na taxonomia de riscos corporativos
As organizações estão adotando uma das três abordagens para colocar o risco de IA em sua estrutura de risco corporativo:
- Tratá-lo como um risco de nível superior, criando uma nova categoria na taxonomia (uma abordagem muito rara, mas útil para obter visibilidade executiva nos estágios iniciais da adoção em massa).
- Tratá-lo como um risco de segundo nível, vinculado ao risco tecnológico, de modelo ou operacional, dentro da taxonomia existente. Tratá-lo como um risco de segundo nível, vinculado ao risco tecnológico, de modelo ou operacional, dentro da taxonomia existente.
- Tratá-lo não como uma categoria independente, mas como um fator transversal que amplia os riscos existentes (risco de modelo, risco de fornecedor, risco de reputação, etc., amplificado pela AI).
Na prática, o rótulo é menos importante do que a capacidade da organização de identificar, prevenir, controlar e mitigar esses riscos de forma sistemática e contínua, com métricas claras, responsabilidades atribuídas e mecanismos de escalonamento definidos.
Implicações estratégicas
O gerenciamento de riscos de IA tornou-se uma decisão estratégica que condiciona a velocidade de adoção, a viabilidade operacional e a credibilidade institucional da organização.
As organizações que abordam a IA principalmente como um projeto de inovação tecnológica enfrentam atritos com a estrutura regulatória, incidentes operacionais e tensões de reputação. A integração da IA desde a sua concepção na arquitetura de governança, controle interno e gestão de riscos permite o dimensionamento com maior estabilidade, menos atrito e maior confiança do órgão regulador, do mercado e dos próprios profissionais.
A vantagem competitiva sustentável decorre de uma maior capacidade de governar a IA: estruturas de controle bem definidas, responsabilidades explícitas, monitoramento contínuo e cultura organizacional que preserva o julgamento humano no centro das decisões críticas.
Regulação, supervisão e padrões de IA
IA, uma atividade regulada
A adoção acelerada da IA e a percepção de seus riscos desencadearam uma resposta regulatória global sem precedentes. Diferentemente dos ciclos tecnológicos anteriores, em que a regulação reagiu com anos de atraso, a IA está sendo regulada paralelamente à sua implantação em massa, justamente porque seus riscos sistêmicos já estão se materializando.
A Europa assumiu a liderança regulatória com o AI Act, a primeira estrutura legal abrangente sobre IA. Iniciativas relevantes nos Estados Unidos, na China, no Reino Unido, no Canadá e em outros países se seguiram, juntamente com um ecossistema crescente de padrões técnicos e estruturas voluntárias que buscam operacionalizar princípios de governança, segurança e ética.
A consequência para as organizações é clara: o gerenciamento da IA não é mais uma questão tecnológica, mas um domínio regulatório estrutural, comparável em impacto à proteção de dados, aos mercados financeiros ou à segurança operacional.
O AI Act: a regulação mais prescritiva
O Regulamento Europeu de IA (Regulamento (UE) 2024/1689) estabelece um modelo regulatório baseado em risco, estruturando obrigações de acordo com o impacto potencial dos sistemas sobre os direitos fundamentais, a segurança e a ordem pública.
A estrutura classifica os sistemas de IA em quatro categorias principais:
1. Risco inaceitável: sistemas proibidos (manipulação cognitiva, pontuação social, certas formas de vigilância biométrica).
2. Alto risco: sistemas usados em áreas críticas, como crédito, emprego, educação, infraestrutura, justiça, saúde, biometria, entre outros. Esse é o núcleo do AI Act.
3. Risco limitado: sistemas que exigem obrigações de transparência.
4. Risco mínimo: sistemas que são livres para uso sob alguns princípios gerais.
Para sistemas de alto risco, o AI Act introduz um conjunto de obrigações estruturais:
- Sistema de gestão de riscos documentado.
- Governança de dados e controle de qualidade de dados.
- Documentação técnica abrangente.
- Registro e rastreabilidade.
- Supervisão humana efetiva.
- Requisitos de precisão, robustez e segurança cibernética.
- Avaliação de compliance prévia à implantação e vigilância contínua pós-comercialização.
As sanções por descumprimento grave do AI Act chega a 35 milhões de euros ou 7% do faturamento global anual, excedendo até mesmo o regime do GDPR (que é de 4%).
Supervisão na Europa: da inovação ao controle permanente
O AI Act cria uma nova arquitetura institucional:
- AI Office: o órgão técnico central da Comissão para IA, especialmente o GPAI.
- Autoridades supervisoras nacionais: supervisionam e sancionam o compliance com o AI Act em cada país.
- AI Board: fórum para coordenação e interpretação comum entre a Comissão e as autoridades nacionais.
- Mecanismos de cooperação transfronteiriça: regras para a coordenação de casos e investigações envolvendo vários Estados-Membros.
A supervisão não se limitará a auditorias pontuais: é estabelecido um modelo de supervisão contínua, com obrigações de relatório, gerenciamento de incidentes graves, retirada de sistemas inseguros e poderes de inspeção comparáveis aos dos reguladores financeiros.
Na prática, a arquitetura de supervisão do AI Act ainda está em construção. O AI Board, órgão central de coordenação entre os Estados-Membros e a Comissão, realizou sua primeira reunião formal em setembro de 2024, e se concentrou em questões organizacionais, códigos de prática para modelos de AIFM e coordenação de autoridades nacionais. As atas revelam um processo ainda em fase de organização: seleção de um presidente, criação de subgrupos e discussão sobre resultados prioritários.
Por sua vez, as autoridades nacionais de supervisão quase não foram designadas. A Espanha criou a AESIA (Agencia Española de Supervisión de la Inteligencia Artificial) em agosto de 2023, tornando-se a primeira autoridade de IA da Europa, e iniciou suas operações efetivas em fevereiro de 2025 com funções de supervisão de sistemas proibidos. Outros Estados-Membros estão em estágios anteriores de designação de autoridades.
O ecossistema de normas: dos princípios à operação
Paralelamente à regulação, uma rede de padrões técnicos e de gerenciamento está se consolidando para estabelecer normas para a prática operacional de IA:
- ISO/IEC 42001: estabelece requisitos para um sistema de gerenciamento de IA (AIMS), no estilo da ISO 27001/9001, para governança e uso responsável da IA.
- ISO/IEC 23894: proporciona um framework detalhado de gestão de riscos de IA ao longo do ciclo de vida, destinado a ser integrado com frameworks de gestão de riscos corporativos.
- ISO/IEC 5259: estrutura e métricas de qualidade de dados de IA.
- NIST AI Risk Management Framework: estrutura focada no gerenciamento de riscos de IA, organizada nas funções Govern-Map-Measure-Manage e orientada para recursos de "trustworthy AI".
- OECD AI Principles: princípios de alto nível (valores humanos, transparência, robustez, responsabilidade, inclusão) que influenciaram diretamente o AI Act e outros marcos regulatórios.
Essas normas têm uma função essencial: estabelecem controles concretos, processos auditáveis e métricas verificáveis. Para muitas organizações, elas estão formando a base técnica de seus programas de compliance.
Fragmentação geopolítica e complexidade operacional
A abordagem europeia baseada em riscos e vinculante não está sendo replicada globalmente:
- Os EUA não têm uma estrutura federal; têm uma abordagem setorial fragmentada por agências (FTC, FDA, EEOC), sem equivalente ao AI Act, complementada por ordens executivas e orientações, além de regulação em vários estados (por exemplo, Califórnia, Colorado, Connecticut, Utah).
- A China articula a IA dentro de uma estratégia estatal de "soberania digital", com regras específicas sobre algoritmos, deepfakes e modelos generativos, forte controle de dados e licenciamento compulsório para determinados sistemas de alto impacto.
- O Reino Unido mantém uma abordagem pró-inovação sem uma lei horizontal de IA, contando com autoridades setoriais e princípios comuns de regulação de IA, com diretrizes e sandboxes regulatórias.
- O Brasil passed a Senate bill in December 2024 structurally similar to the AI Act, featuring a risk-based approach (prohibited/high/limited/minimal), specific obligations for high-risk systems, fines up to R$50 million or 2% of turnover. The bill is pending approval in the Chamber of Deputies, with entry into force expected one year after enactment.
- O México lacks specific AI regulation: more than 60 bills have been submitted since 2020 without approval. In February 2025 a constitutional reform was introduced to grant the federal government competence over AI, which should lead to a General Law. Until then, there is no specific legal framework, only voluntary guidelines aligned with UNESCO and OECD principles.
- A Austrália mantém uma abordagem voluntária e baseada em princípios: AI Ethics Principles (2019, 8 princípios voluntários) e Guidance for AI Adoption (outubro de 2025, substituindo o Voluntary AI Safety Standard de 2024). Não há legislação vinculante específica para IA, e o governo preferiu reforçar as leis existentes (privacidade, consumidor, setoriais).
Implicações estratégicas
Os estudos concordam que a divergência entre esses modelos (UE mais prescritiva, EUA fragmentado e setorial, China altamente centralizada, Reino Unido e Austrália mais baseados em princípios) força as empresas globais a segmentar produtos, modelos e processos de compliance por jurisdição.
Isso se traduz em arquiteturas de IA de vários níveis (governança, dados, MLOps, documentação) projetadas para mapear e conciliar simultaneamente requisitos divergentes, aumentando a complexidade operacional de maneiras sem precedentes para muitos setores tradicionalmente menos regulados.
IA e segurança cibernética
Uma batalha com novas regras e novas superfícies de ataque
A IA está transformando radicalmente a segurança cibernética em três dimensões simultâneas: amplia os recursos ofensivos dos invasores, aprimora as defesas das organizações e, ao mesmo tempo, introduz novas vulnerabilidades que exigem proteção direcionada.
IA ofensiva: automação e adaptação em escala industrial
Os atacantes adotaram a IA com uma velocidade surpreendente, transformando métodos tradicionais em ameaças qualitativamente diferentes. O impacto é quantificável: mais de 28 milhões de ataques cibernéticos com IA foram registrados globalmente em 2025, um aumento de 47% em relação ao ano anterior; o setor financeiro foi o mais afetado, com 33% desses ataques; e 87% das organizações sofreram pelo menos um ataque assistido por IA nos últimos 12 meses.
Phishing hiperpersonalizado em grande escala. Os ataques de phishing gerados por IA aumentaram em 1.265% no ano desde o lançamento do ChatGPT, e mais de 80% dos e-mails de phishing agora usam modelos de linguagem para geração de texto. A diferença qualitativa é dramática: enquanto o phishing tradicional atinge taxas de sucesso de 12%, as campanhas geradas por IA atingem taxas de cliques de 54%. Os LLMs permitem a criação de mensagens personalizadas por meio da análise de perfis públicos, estilo de redação corporativa e contextos específicos da vítima, em velocidades e volumes impossíveis de serem criados manualmente.
Malware polimórfico adaptável. 76% dos malwares detectados em 2025 exibem características polimórficas alimentadas por IA. Diferentemente do malware polimórfico tradicional (que sofre mutação por meio de ofuscação ou criptografia de rotina), o malware gerado por IA reescreve dinamicamente seu código em tempo real, mantendo a funcionalidade idêntica, mas com assinaturas completamente diferentes. Algumas variantes avançadas geram versões exclusivas a cada 15 segundos durante um ataque. Isso derrota os sistemas de detecção baseados em assinaturas estáticas, que historicamente têm sido a base dos antivírus tradicionais.
Mais preocupante: a IA não apenas gera variantes, mas adapta o comportamento. Os modelos de machine learning incorporados no malware analisam o ambiente de execução, detectam sistemas de monitoramento e ajustam suas táticas em tempo real para evitar a detecção.
Deepfakes e manipulação de identidade. De acordo com a análise de segurança cibernética, baseada no IC3 2025, os ataques de BEC (Business E-mail Compromise) assistidos por IA aumentaram cerca de 37%, combinando texto, áudio e vídeo sintéticos para se passar por executivos. O caso mais notório: um deepfake de áudio do Ministro da Defesa da Itália que causou perdas financeiras significativas. Em uma pesquisa, 85% das organizações relataram ter sofrido um ataque de deepfake em 2025.
Dark LLMs e ferramentas ofensivas especializadas. Modelos de linguagem modificados especificamente para crimes cibernéticos proliferaram: HackerGPT, WormGPT, GhostGPT, FraudGPT. Esses sistemas, criados por jailbreaking de modelos éticos ou modificando modelos de código aberto, são comercializados em fóruns da dark web com modelos de assinatura e suporte técnico. Eles geram scripts maliciosos, exploits e campanhas de engenharia social sem restrições éticas.
IA defensiva: detecção comportamental e resposta automatizada
As organizações estão respondendo com IA defensiva igualmente sofisticada. 51% das empresas usam IA ou automação na segurança atualmente, e a adoção está se acelerando rapidamente com evidências de ROI demonstrável.
Análise comportamental e detecção de anomalias. Os sistemas de análise de comportamento de usuários e instituições (UEBA) com tecnologia de IA estabelecem linhas de base dinâmicas de comportamento normal para usuários, dispositivos e aplicativos, analisando bilhões de eventos diários. Em vez de procurar por assinaturas conhecidas, eles detectam desvios sutis dos padrões estabelecidos. Esse recurso é essencial contra malware polimórfico e ataques de dia zero: em ambientes de alto risco, os sistemas baseados em IA atingem taxas de detecção de até 98%, diante de ameaças conhecidas ou que apresentam padrões anômalos reconhecíveis. Diante de ataques genuinamente inéditos — sem assinatura nem padrão comportamental prévio — a detecção baseada em comportamento reduz o risco, mas não elimina a incerteza: a IA defensiva não reconhece a nova ameaça, mas detecta seu desvio da norma, o que implica que ataques suficientemente cautelosos ou bem projetados para imitar um comportamento legítimo podem escapar desta detecção inicial.
Plataformas SIEM/XDR/SOAR com IA integrada. As plataformas atuais de gerenciamento de informações e eventos de segurança (SIEM), detecção e resposta estendidas (XDR) e orquestração, automação e resposta de segurança (SOAR) integram nativamente a IA para correlacionar eventos entre sistemas diferentes, reduzir falsos positivos (até 95% de redução em implantações maduras) e automatizar a resposta. A CrowdStrike relata que sua plataforma Falcon analisa 4,7 bilhões de eventos diariamente com caça a ameaças alimentada por IA 24 horas por dia, 7 dias por semana. O Microsoft Sentinel demonstrou reduções de 30% no tempo médio de resposta (MTTR) por meio de correlação e análise comportamental baseadas em IA.
Impacto econômico demonstrável. De acordo com a IBM, as organizações que usam IA e automação extensivamente na segurança reduzem os custos médios de violação em US$ 1,9 milhão (mais de 50% menos do que as organizações sem IA) e encurtam os ciclos de contenção em 80 dias, em média. As organizações com plataformas orientadas por IA detectam ameaças 60% mais rápido e alcançam 95% de precisão na detecção.
Multiplicação de capacidades. A IA atua como um multiplicador de recursos para as equipes de segurança: ela automatiza a triagem de alertas (as organizações enfrentam uma média de 4.500 alertas por dia), executa manuais de resposta automática para ameaças conhecidas e permite que analistas juniores operem em níveis mais altos de eficácia. Noventa e cinco por cento dos profissionais de segurança relatam que a IA melhora sua velocidade e eficiência na prevenção, detecção, resposta e recuperação de ataques.
Assimetria e o dilema estratégico
Apesar dos recursos defensivos avançados, persiste uma assimetria preocupante: atualmente, a maioria das empresas não tem maturidade suficiente para combater as ameaças avançadas com IA. 78% dos CISOs afirmam que as ameaças baseadas em IA agora têm um "impacto significativo" em suas organizações.
A segurança cibernética se tornou uma batalha de IA contra IA, com ambos os lados operando em velocidades de máquina. Os atacantes automatizam o reconhecimento, geram explorações personalizadas e adaptam suas táticas em tempo real. Os defensores correlacionam terabytes de telemetria, preveem vetores de ataque e executam a contenção autônoma. O diferencial competitivo não está mais em ter IA, mas na sofisticação dos modelos, na qualidade dos dados de treinamento, na velocidade das atualizações de inteligência contra ameaças e na capacidade de integração entre as superfícies de ataque.
Protegendo a IA: vulnerabilidades próprias
Além da batalha entre IA ofensiva e defensiva, surge uma terceira dimensão crítica: a securitização dos próprios sistemas de IA, que introduzem vetores de ataque sem precedentes no software tradicional. Os modelos de IA são vulneráveis a ataques adversários específicos: data poisoning, em que os invasores injetam dados maliciosos para degradar o modelo; evasão adversária por meio de perturbações imperceptíveis que enganam o modelo durante a inferência; e mineração de modelos por meio de consultas repetidas para roubar propriedade intelectual.
Os LLMs acrescentam vetores adicionais documentados pela OWASP: prompt injection (instruções maliciosas incorporadas em entradas que alteram o comportamento do modelo), insecure output handling (aplicativos que dependem cegamente de saídas sem validação), training data poisoning, model denial of service e vulnerabilidades da cadeia de suprimentos. O NIST publicou em 2024 diretrizes específicas para o desenvolvimento seguro de IA generativa, ampliando seu SSDF com controles diferenciados para cada fase do ciclo de vida. A securitização eficaz exige uma curadoria rigorosa do dataset, adversarial robustness testing, validação de inputs/outputs, sandboxing e red teaming específico de ML. As equipes de segurança devem incorporar expertise em ataques de adversários; os frameworks de governança devem considerar a IA como uma superfície de ataque independente com seus próprios controles.
O crime cibernético global movimenta trilhões anualmente. As organizações devem manter uma governança robusta: os próprios sistemas defensivos de IA agora são alvos de ataques (envenenamento de modelos, prompt injection, evasão adversária), criando uma meta camada de risco que exige proteção especializada.
IA, privacidade e propriedade intelectual
Um conflito estrutural
A adoção em massa da IA generativa reabre debates fundamentais sobre privacidade e propriedade intelectual, confrontando os modelos de negócios, de sistemas que exigem dados massivos, com estruturas legais projetadas para minimização e controle individual. As tensões não são meramente técnicas: elas refletem choques estruturais entre a lógica operacional dos LLMs e os princípios que regem a proteção de dados e os direitos autorais.
Privacidade em LLMs: riscos sistêmicos em todo o ciclo de vida
Em abril de 2025, o European Data Protection Board (EDPB) publicou um relatório abrangente sobre os riscos de privacidade em LLMs, desenvolvido no âmbito de seu programa Support Pool of Experts. O documento identifica que cada fase do ciclo de vida do LLM introduz riscos específicos de privacidade e proteção de dados:
- Memorização não intencional e vazamento de dados pessoais. Os LLMs podem memorizar fragmentos de dados pessoais presentes em conjuntos de dados de treinamento e reproduzi-los posteriormente nos resultados gerados. Esse fenômeno não é um bug ocasional, mas um comportamento intrínseco: o modelo armazena padrões estatísticos que incluem dados confidenciais. O EDPB documenta casos em que prompts específicos conseguiram extrair informações pessoais (nomes, e-mails, números de telefone, dados médicos) que estavam nos dados de treinamento. A magnitude do problema aumenta de acordo com o tamanho do modelo e a sensibilidade dos dados processados.
- Reidentificação e criação de perfis não intencionais. Embora os dados sejam anônimos antes do treinamento, as técnicas de inferência podem reidentificar indivíduos combinando várias saídas do modelo. O EDPB alerta que os LLMs podem gerar perfis detalhados de indivíduos sem o processamento explícito de dados pessoalmente identificáveis, o que viola os princípios de minimização e finalidade do GDPR.
- Feedback loops sem salvaguardas. As interações dos usuários com chatbots são frequentemente armazenadas para posterior ajuste fino dos modelos, de modo que os dados confidenciais revelados nas conversas são incorporados ao modelo sem consentimento explícito ou garantias de exclusão posterior.
- Incompatibilidade estrutural com o GDPR. O relatório do EDPB destaca tensões irresolúveis com os princípios do GDPR:
o Minimização de dados: os LLMs exigem conjuntos de dados enormes, o que está em contradição direta com a minimização
o Direito de ser esquecido: ainda não existem métodos robustos para "destreinar" seletivamente os modelos (as técnicas emergentes, como o machine unlearning, ainda estão em fase experimental).
o Transparência: as arquiteturas de transformadores são caixas pretas em que o rastreamento da origem de saídas específicas é tecnicamente complexo.
o Consentimento: dados extraídos da Internet raramente incluem consentimento para uso em treinamento de IA.
- Avaliação de impacto obrigatória. O EDPB conclui que, dada a natureza sistêmica do processamento nos LLMs, a realização da Data Protection Impact Assessment (DPIA) de acordo com o Art. 35 do GDPR não é apenas recomendada, mas obrigatória na maioria dos casos, especialmente quando os LLMs processam dados confidenciais ou tomam decisões com impacto sobre os indivíduos.
- Mitigações técnicas com custo. O relatório propõe medidas como differential privacy (adição de ruído estatístico para impedir a identificação), federated learning (modelos de treinamento sem centralização de dados), Retrieval-Augmented Generation (RAG, que separa o conhecimento atualizável da memória LLM estática) e retrospective logging minimization (minimização de dados nos registros do sistema). No entanto, todas essas técnicas implicam em precisão reduzida, alto custo computacional ou funcionalidade reduzida.
Propriedade intelectual: litígios em massa e colapso da infraestrutura
A World Intellectual Property Organization (OMPI) dedicou várias sessões de sua "WIPO Conversation on IP and AI" (Conversa da OMPI sobre PI e IA) para analisar o impacto da IA generativa sobre os direitos autorais. As últimas sessões se concentraram especificamente na infraestrutura para gerenciamento de direitos, atribuição e compensação na era da IA generativa.
Dados de treinamentox: uso justo ou violação em massa? O debate central não está resolvido. As empresas de IA argumentam que os modelos de treinamento com conteúdo protegido constituem "uso justo", análogo à forma como os humanos aprendem lendo. Os detentores de direitos argumentam que é a cópia não autorizada em escala industrial com intenção comercial que cria substitutos de mercado para o conteúdo original.
Os litígios estão se multiplicando; para citar alguns exemplos:
- New York Times vs. OpenAI/Microsoft: o NYT processa o uso de milhões de artigos sem consentimento, argumentando que os modelos criam substitutos de mercado que desviam o tráfego de seu paywall e geram alucinações que prejudicam sua reputação. Ele reivindica bilhões de dólares em danos.
- Getty Images vs. Stability AI: a Getty alega uso não consensual de mais de 12 milhões de fotografias para treinar o Stable Diffusion, incluindo violação de marca registrada (já que o modelo replica a marca d'água da Getty).
- Artistas vs. Midjourney/Stability AI: os artistas alegam que suas obras foram extraídas sem permissão para treinar modelos de geração de imagens.
- Gravadoras vs. Anthropic: a Universal Music Group (UMG) e outras gravadoras estão processando por violação massiva do uso de letras de músicas.
Em dezembro de 2025, mais de 72 processos ativos de direitos autorais contra empresas de IA estavam em andamento. Até o momento, três juízes emitiram decisões preliminares sobre o uso justo: duas decisões a favor das empresas de IA, uma contra. As decisões finais não são esperadas até o verão de 2026, no mínimo.
Propriedade dos resultados: um vácuo jurídico: Quem é o proprietário do conteúdo gerado por IA? A maioria das jurisdições (incluindo o US Copyright Office) sustenta que os direitos autorais exigem autoria humana com "input criativo suficiente". O conteúdo gerado exclusivamente por IA sem intervenção humana significativa é de domínio público. Mas os limites são imprecisos: quanta intervenção humana (prompt engineering, seleção, pós-edição) é "suficiente"?
Collapse of copyright infrastructure: A WIPO alerta que os sistemas de gestão coletiva de direitos, projetados para volumes gerenciáveis de trabalhos humanos, estão entrando em colapso diante dos trilhões de resultados gerados pela IA diariamente. Não existem infraestruturas escalonáveis para rastreamento, atribuição e compensação. Sessões recentes da WIPO exploraram a necessidade de novas infraestruturas técnicas e estruturas regulatórias, mas as soluções práticas continuam especulativas.
Fragmentação e falta de consenso global
A fragmentação regulatória amplia a incerteza. A UE exige transparência nos dados de treinamento (AI Act Art. 53), os EUA não têm legislação federal específica e a China impõe um controle estatal rigoroso sobre dados e algoritmos. As empresas que operam globalmente enfrentam requisitos não harmonizados.
As tecnologias de preservação da privacidade (differential privacy, federated learning, homomorphic encryption) oferecem caminhos técnicos para conciliar a privacidade com a utilidade da IA, mas estão longe de serem adotadas em massa: são caras, complexas e reduzem o desempenho. A tensão entre a inovação tecnológica acelerada e as estruturas jurídicas projetadas para paradigmas anteriores continua, por enquanto, sem solução.
Índice deconteúdos

Introdução

Resumo Executivo

A explosão da tecnologia de IA


Governança da IA e impacto sobre as pessoas

Fronteiras da IA

Estudo de caso: GenMS™ Sybil

Conclusões

Referências e glossário