Tendencias en IA
Riesgos, regulación y seguridad de la IA
Vídeo: Tendencias en IA
Índice de la publicación
Documento completo
Acceder a GenMS™ Sybil
La IA generativa y los sistemas agénticos ofrecen capacidades transformadoras, pero introducen riesgos estructurales que ya no son hipotéticos: se están materializando en producción. La Declaración de Bletchley advirtió explícitamente sobre impactos de la IA potencialmente «catastróficos», y la experiencia acumulada confirma que la lista de riesgos es larga y diversa. Esta sección analiza los riesgos de la IA, los marcos regulatorios y el gobierno de la IA, la batalla entre IA defensiva y adversaria en ciberseguridad, y las tensiones abiertas en privacidad y propiedad intelectual.
Riesgos de la IA
La IA no crea el riesgo: lo amplifica
La adopción de la IA no introduce, salvo excepciones, riesgos sustancialmente nuevos – sino que amplifica de forma drástica riesgos ya existentes: operacional, de modelo, tecnológico, de proveedor, legal, reputacional, de cumplimiento, estratégico, social, etc. La diferencia no está en la naturaleza del riesgo, sino en su velocidad de propagación, escala de impacto y dificultad de contención.
Salvo algunas categorías emergentes (como la generación de contenido tóxico, ciertas formas de manipulación cognitiva mediante deepfakes, o ataques de prompt injection), la mayor parte de los riesgos asociados a la IA son versiones aceleradas, automatizadas y masivas de problemas conocidos. Un sesgo algorítmico es, en esencia, un sesgo humano sistematizado y replicado millones de veces. Una fuga de información por mal uso de un chatbot es, a fin de cuentas, una fuga de información.
Cuatro dimensiones interconectadas
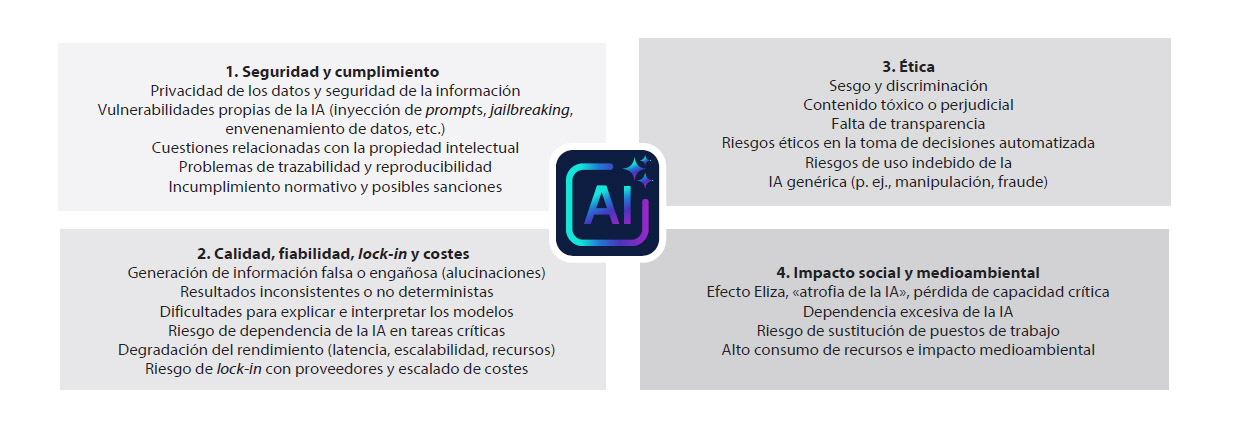
En la práctica, estos riesgos se materializan en cuatro grandes dimensiones (Fig. 3):
1. Seguridad y cumplimiento
La IA introduce nuevas superficies de ataque y complica el cumplimiento normativo. La privacidad y seguridad de la información enfrentan amenazas específicas: fugas involuntarias de datos confidenciales, vulnerabilidades técnicas emergentes como prompt injection (instrucciones maliciosas embebidas en inputs que «engañan» al modelo para ignorar restricciones) o jailbreaks (técnicas para eludir controles de seguridad), y exposición accidental de información sensible cuando profesionales utilizan herramientas no securizadas.
La propiedad intelectual se vuelve ambigua: ¿quién es titular del código generado por IA? ¿Qué ocurre cuando un modelo reproduce fragmentos protegidos por derechos de autor? Como ejemplo, el New York Times tiene un litigio abierto con OpenAI/Microsoft por usar contenidos con copyright sin licencia, entre otras muchas demandas en curso.
La trazabilidad y reproducibilidad se degradan cuando las decisiones críticas dependen de modelos que evolucionan continuamente mediante reentrenamiento automático, haciendo difícil reconstruir exactamente qué versión del sistema produjo qué resultado en qué momento.
Y el incumplimiento normativo tiene ahora consecuencias financieras directas y visibles: el AI Act europeo establece multas de hasta 35 millones de euros o el 7% de la facturación global anual, lo que convierte el cumplimiento en IA en riesgo material de primer orden, superior incluso al de protección de datos.
2. Calidad, fiabilidad, lock-in y costes
Como ya se ha dicho, la IA generativa produce por diseño salidas plausibles, no necesariamente correctas. Las alucinaciones (generación de información falsa presentada con confianza) no son bugs ocasionales, sino comportamientos intrínsecos del diseño actual de los modelos. El comportamiento no determinista implica que el mismo input puede producir outputs distintos en el mismo modelo, lo que complica la validación, auditoría y certificación de procesos críticos.
El model drift silencioso representa uno de los riesgos más insidiosos: un modelo que funcionaba correctamente puede degradarse en poco tiempo porque la distribución de datos cambió, sin que existan mecanismos de monitorización que generen alertas tempranas. Un modelo puede seguir operando con apariencia de normalidad hasta que alguien detecta manualmente las anomalías en los resultados.
La dependencia excesiva de la IA en tareas críticas crea fragilidad operativa: si el sistema de IA falla, cae o se vuelve prohibitivamente caro, ¿puede la organización seguir operando? ¿Existen procedimientos de contingencia humanos? Y la pérdida de control humano efectivo ocurre cuando las decisiones se delegan a sistemas cuyo razonamiento interno es opaco incluso para quienes los desarrollan y operan.
Más aún, las organizaciones construyen dependencias estructurales sobre pocos proveedores de modelos (OpenAI, Anthropic, Google) e infraestructura (AWS, Azure, GCP). Cambios en pricing, términos de servicio o caídas operativas pueden paralizar procesos críticos simultáneamente. Migrar entre ecosistemas implica reescribir integraciones, reentrenar workflows, recertificar compliance y asumir costes prohibitivos, lo que no siempre es factible; la diversificación de proveedores, aunque costosa, es la respuesta estructural a este riesgo.
A los riesgos anteriores se añade una dimensión económica que los marcos de gestión tradicionales infravaloran. Los costes unitarios de inferencia caen estructuralmente (aproximadamente 10x cada 12 meses) pero esa caída no protege contra el crecimiento exponencial del volumen: los sistemas agénticos tienen estructuras de coste con escalabilidad no lineal, cada agente multiplica llamadas a modelos y herramientas, y sin monitorización de tokens en tiempo real ni límites de gasto explícitos desde el diseño, un prototipo viable puede convertirse en un sistema insostenible antes de que nadie lo detecte. A esto se suma la incertidumbre sobre el retorno de la inversión: la pregunta de si el gasto masivo en IA generará el valor esperado no tiene aún respuesta consolidada, y muchas organizaciones avanzan impulsadas por la presión competitiva más que por un caso de negocio robusto. Gartner sintetiza ambos riesgos en una predicción: más del 40% de los proyectos agénticos serán cancelados antes de 2027 por escalada de costes, valor de negocio poco claro y controles de riesgo inadecuados. El lock-in agrava el problema estructuralmente: la dependencia de un único proveedor elimina la capacidad de migrar a arquitecturas más eficientes cuando estén disponibles.
3. Ética y toma de decisiones automatizada
Los sesgos algorítmicos amplifican sesgos presentes en datos históricos: si un modelo de selección de personal se entrena con datos de una organización históricamente sesgada hacia ciertos perfiles, el modelo sistematizará y escalará ese sesgo. La falta de transparencia y las dificultades de explicabilidad complican el cumplimiento de requisitos regulatorios que exigen que las decisiones automatizadas sean comprensibles y justificables, especialmente cuando afectan derechos fundamentales.
Las decisiones automatizadas con impacto humano directo (aprobación de créditos, diagnósticos médicos, evaluación de riesgos penales o selección de candidatos) plantean problemas de responsabilidad: ¿quién responde cuando el modelo comete un error con consecuencias graves? ¿El proveedor del modelo base, el equipo que lo personalizó, el usuario que escribió el prompt, el comité que aprobó su despliegue? La cadena de responsabilidad se vuelve compleja, lo que genera vacíos de accountability que ni la regulación ni la práctica han resuelto completamente.
4. Impacto social y organizativo
La transformación del empleo ya no es especulativa: tareas manuales y cognitivas rutinarias enfrentan automatización acelerada, y las organizaciones deben gestionar transiciones laborales, programas de reskilling y expectativas regulatorias y sociales crecientes sobre responsabilidad corporativa.
La dependencia cognitiva y erosión de capacidades críticas representa un riesgo de primer orden: si una generación entera de profesionales aprende a trabajar exclusivamente con IA como intermediario, ¿mantienen la intuición y el conocimiento suficientes para valorar críticamente los resultados? ¿Qué ocurre cuando la IA no está disponible? Y la presión sobre recursos y huella medioambiental no es trivial: entrenar modelos avanzados consume energía equivalente a miles de hogares durante meses, y el escalado masivo de inferencia plantea interrogantes sobre sostenibilidad a largo plazo.
Figura 3. Algunos riesgos de la IA generativa.
 |
Amplificación no lineal
La IA introduce un fenómeno clave en la gestión del riesgo: la amplificación no lineal. Un fallo menor (un sesgo en datos, un prompt mal diseñado o una mala configuración de permisos) puede escalar en minutos y afectar simultáneamente a procesos, clientes, reguladores y reputación. Cuanto mayor es la autonomía y la integración de la IA en procesos críticos, mayor es el radio de impacto del fallo, lo que exige diseñar desde el inicio mecanismos de contención proporcionales a esa escala. Un ejemplo concreto: un modelo de atención al cliente que, tras un cambio menor en el prompt del sistema, empieza a revelar información confidencial de otros clientes en «tan solo» el 0,01% de las conversaciones, lo que es casi indetectable en las pruebas. En un sistema que gestiona 100.000 interacciones diarias, esto significa 10 filtraciones al día antes de que se detecte el patrón. Cuando se identifica el problema, ya se han producido cientos de incidentes, cada uno con implicaciones regulatorias, contractuales y reputacionales.
IA en la taxonomía de riesgos corporativos
Las organizaciones están adoptando uno de tres enfoques para ubicar el riesgo de IA en su marco de riesgos corporativo:
- Tratarlo como riesgo de primer nivel, creando una categoría nueva en la taxonomía (enfoque muy poco frecuente, pero útil para ganar visibilidad ejecutiva en fases tempranas de adopción masiva).
- Tratarlo como riesgo de segundo nivel, vinculado a riesgo tecnológico, de modelo u operacional, dentro de la taxonomía existente.
- No tratarlo como categoría independiente, sino como driver transversal que amplifica riesgos existentes (riesgo de modelo, de proveedor, reputacional, etc., amplificado por IA).
En la práctica, la etiqueta es menos importante que la capacidad de la organización para identificar, prevenir, controlar y mitigar estos riesgos de forma sistemática y continua, con métricas claras, responsabilidades asignadas y mecanismos de escalado definidos.
Implicación estratégica
La gestión del riesgo en IA se ha convertido en una decisión estratégica que condiciona la velocidad de adopción, la viabilidad operativa y la credibilidad institucional de la organización.
Las entidades que enfocan la IA principalmente como proyecto de innovación tecnológica encuentran fricciones con el marco regulatorio, incidentes operativos y tensiones reputacionales. Integrar la IA desde su concepción dentro de la arquitectura de gobierno, control interno y gestión de riesgos permite escalar con mayor estabilidad, menor fricción y mayor confianza por parte del regulador, del mercado y de los propios profesionales.
La ventaja competitiva sostenible surge de una mayor capacidad para gobernar la IA: marcos de control bien definidos, responsabilidades explícitas, monitorización continua y cultura organizativa que preserve el juicio humano como elemento central de las decisiones críticas.
Regulación, supervisión y estándares de IA
La IA, una actividad regulada
La aceleración de la adopción de la IA y la constatación de sus riesgos han desencadenado una respuesta regulatoria global sin precedentes. A diferencia de ciclos tecnológicos anteriores, donde la regulación reaccionaba con años de retraso, la IA está siendo regulada en paralelo a su despliegue masivo, precisamente porque sus riesgos sistémicos ya se están materializando.
Europa ha asumido el liderazgo normativo con el AI Act, el primer marco legal integral sobre IA. Le siguen iniciativas relevantes en Estados Unidos, China, Reino Unido, Canadá y otros países, junto con un ecosistema creciente de estándares técnicos y marcos voluntarios que buscan operacionalizar principios de gobernanza, seguridad y ética.
La consecuencia para las organizaciones es clara: la gestión de IA deja de ser una cuestión tecnológica para convertirse en un dominio regulatorio estructural, comparable en impacto al de protección de datos, mercados financieros o seguridad operacional.
El AI Act: la regulación más prescriptiva
El Reglamento Europeo de IA (Reglamento (UE) 2024/1689) establece un modelo de regulación basado en el riesgo, estructurando las obligaciones según el impacto potencial de los sistemas sobre los derechos fundamentales, la seguridad y el orden público.
El marco clasifica los sistemas de IA en cuatro categorías principales:
1. Riesgo inaceptable: sistemas prohibidos (manipulación cognitiva, puntuación social, ciertas formas de vigilancia biométrica).
2. Riesgo alto: sistemas utilizados en ámbitos críticos como crédito, empleo, educación, infraestructuras, justicia o sanidad, biometría, entre otros. Es el núcleo del AI Act.
3. Riesgo limitado: sistemas que requieren obligaciones de transparencia.
4. Riesgo mínimo: sistemas de uso libre bajo algunos principios generales.
Para los sistemas de alto riesgo, el AI Act introduce un conjunto de obligaciones estructurales:
- Sistema de gestión de riesgos documentado.
- Gobierno y control de calidad de datos.
- Documentación técnica exhaustiva.
- Registro de logs y trazabilidad.
- Supervisión humana efectiva.
- Requisitos de precisión, robustez y ciberseguridad.
- Evaluación de conformidad previa al despliegue y vigilancia continua post-mercado.
Las sanciones por incumplimiento grave del AI Act alcanzan los 35 millones de euros o el 7% de la facturación global anual, superando incluso el régimen del GDPR (que alcanza el 4%).
Supervisión en Europa: de la innovación al control permanente
El AI Act crea una arquitectura institucional nueva:
- AI Office: órgano técnico central de la Comisión para IA, sobre todo GPAI.
- Autoridades nacionales de supervisión: supervisan y sancionan el cumplimiento del AI Act en cada país.
- AI Board: foro de coordinación e interpretación común entre la Comisión y las autoridades nacionales.
- Mecanismos de cooperación transfronteriza: reglas para coordinar casos e investigaciones que afecten a varios Estados miembros.
La supervisión no se limitará a auditorías puntuales: se establece un modelo de vigilancia continua, con obligaciones de reporting, gestión de incidentes graves, retirada de sistemas no seguros y poderes de inspección comparables a los de reguladores financieros.
En la práctica, la arquitectura supervisora del AI Act aún está en fase de construcción. El AI Board, órgano central de coordinación entre Estados miembros y la Comisión, celebró su primera reunión formal en septiembre de 2024, y se ha centrado en cuestiones organizativas, códigos de práctica para modelos GPAI y coordinación de autoridades nacionales. Las actas revelan un proceso aún en fase de organización: selección de presidencia, creación de subgrupos y discusión sobre entregables prioritarios.
Por su parte, las autoridades nacionales de supervisión apenas han sido designadas. España creó la AESIA (Agencia Española de Supervisión de la Inteligencia Artificial) en agosto de 2023, convirtiéndose en la primera autoridad de IA de Europa, y comenzó operaciones efectivas en febrero de 2025 con funciones de supervisión de sistemas prohibidos. Otros Estados miembros están en fases más tempranas de designación de autoridades.
El ecosistema de estándares: de los principios a la operación
En paralelo a la regulación, se consolida un entramado de estándares técnicos y de gestión que buscan establecer normas para la práctica operativa de la IA; entre ellos:
- ISO/IEC 42001: establece requisitos para un sistema de gestión de IA (AIMS), al estilo ISO 27001/9001, para gobernanza y uso responsable de la IA.
- ISO/IEC 23894: proporciona un marco detallado de gestión de riesgos de IA a lo largo del ciclo de vida, pensado para integrarse con frameworks de gestión de riesgos corporativos.
- ISO/IEC 5259: marco y métricas para calidad del dato en IA.
- NIST AI Risk Management Framework: marco centrado en la gestión de riesgos de IA, organizado en las funciones Govern-Map-Measure-Manage y orientado a características de «trustworthy AI».
- OECD AI Principles: principios de alto nivel (valores humanos, transparencia, robustez, accountability, inclusión) que han influido directamente en el AI Act y otros marcos regulatorios.
Estos estándares cumplen una función esencial: establecen controles concretos, procesos auditables y métricas verificables. Para muchas organizaciones, están constituyendo la base técnica de sus programas de cumplimiento.
Fragmentación geopolítica y complejidad operativa
El enfoque europeo basado en riesgo y vinculante no se está replicando globalmente:
- Estados Unidos carece de marco federal; dispone de un enfoque sectorial fragmentado por agencias (FTC, FDA, EEOC), sin equivalente al AI Act, complementado por órdenes ejecutivas y guías, y de regulación en varios de los Estados (e.g., California, Colorado, Connecticut, Utah).
- China articula la IA dentro de una estrategia estatal de «soberanía digital», con normas específicas sobre algoritmos, deepfakes y modelos generativos, fuerte control de datos y licencias obligatorias para ciertos sistemas de alto impacto.
- Reino Unido mantiene un enfoque pro‑innovación sin una ley horizontal de IA, apoyándose en autoridades sectoriales y principios comunes de regulación de IA, con guías y sandboxes regulatorios.
- Brasil aprobó en el Senado (diciembre 2024) un proyecto de ley estructuralmente similar al AI Act: enfoque basado en riesgo (prohibido/alto/limitado/mínimo), obligaciones específicas para sistemas de alto riesgo, multas hasta R$50 millones o 2% de facturación. El proyecto está pendiente de aprobación en la Cámara de Diputados, con entrada en vigor prevista un año después de su promulgación.
- México carece de regulación: desde 2020 se han presentado más de 60 proyectos de ley sin aprobación. En febrero de 2025 se introdujo una reforma constitucional para otorgar competencia federal en IA, que debe traducirse en Ley General. Hasta entonces, no existe marco legal específico, solo guías voluntarias alineadas con UNESCO y OCDE.
- Australia mantiene un enfoque voluntario y basado en principios: AI Ethics Principles (2019, 8 principios voluntarios) y Guidance for AI Adoption (octubre 2025, sustituyendo el Voluntary AI Safety Standard de 2024). No hay legislación vinculante específica para IA, y el gobierno ha preferido reforzar leyes existentes (privacidad, consumidor, sectorial).
Implicaciones estratégicas
Los estudios coinciden en que la divergencia entre estos modelos (UE más prescriptiva, EE. UU. fragmentado y sectorial, China altamente centralizada, Reino Unido y Australia más principle-based) obliga a las compañías globales a segmentar productos, modelos y procesos de cumplimiento por jurisdicción. Esto se traduce en arquitecturas de IA multinivel (gobernanza, datos, MLOps, documentación) diseñadas para mapear y reconciliar simultáneamente requisitos divergentes, lo que incrementa la complejidad operativa de forma sin precedentes para muchos sectores tradicionalmente menos regulados.
IA y ciberseguridad
Una batalla con nuevas reglas y nuevas superficies de ataque
La IA está transformando radicalmente la ciberseguridad en tres dimensiones simultáneas: amplifica las capacidades ofensivas de los atacantes, potencia las defensas de las organizaciones y, al mismo tiempo, introduce nuevas vulnerabilidades que requieren protección específica.
IA ofensiva: automatización y adaptación a escala industrial
Los atacantes han adoptado IA con velocidad sorprendente, transformando métodos tradicionales en amenazas cualitativamente diferentes. El impacto es cuantificable: en 2025 se registraron más de 28 millones de ciberataques potenciados por IA globalmente, un incremento del 47% interanual; el sector financiero fue el más afectado, con un 33% de estos ataques; y el 87% de las organizaciones experimentaron al menos un ataque asistido por IA en los últimos 12 meses.
Phishing hiperpersonalizado a escala masiva. Los ataques de phishing generados por IA aumentaron un 1.265% en un año desde el lanzamiento de ChatGPT, y más del 80% de los emails de phishing utilizan ahora modelos de lenguaje para generación de texto. La diferencia cualitativa es dramática: mientras el phishing tradicional alcanza tasas de éxito del 12%, las campañas generadas por IA logran 54% de clics. Los LLMs permiten crear mensajes personalizados analizando perfiles públicos, estilo de escritura corporativa y contextos específicos de la víctima, a velocidades y volúmenes imposibles manualmente.
Malware polimórfico adaptativo. El 76% del malware detectado en 2025 exhibe características polimórficas potenciadas por IA. A diferencia del malware polimórfico tradicional (que muta mediante ofuscación o encriptación rutinaria), el malware generado por IA reescribe dinámicamente su código en tiempo real, manteniendo funcionalidad idéntica, pero con firmas completamente diferentes. Algunas variantes avanzadas generan versiones únicas cada 15 segundos durante un ataque. Esto derrota a los sistemas de detección basados en firmas estáticas, que históricamente han sido la base de los antivirus tradicionales.
Más preocupante: la IA no solo genera variantes, sino que adapta el comportamiento. Los modelos de machine learning embebidos en malware analizan el entorno de ejecución, detectan sistemas de monitorización y ajustan sus tácticas en tiempo real para evadir la detección.
Deepfakes y manipulación de identidad. Según análisis de ciberseguridad basados en el IC3 2025, los ataques de Business Email Compromise (BEC) asistidos por IA habrían aumentado alrededor de un 37%, combinando texto, audio y vídeo sintéticos para suplantar a directivos. El caso más notorio: un deepfake de audio del Ministro de Defensa italiano que causó pérdidas financieras significativas. En una encuesta, el 85% de las organizaciones reportaron haber experimentado algún ataque mediante deepfake en 2025.
Dark LLMs y herramientas ofensivas especializadas. Han proliferado modelos de lenguaje modificados específicamente para cibercrimen: HackerGPT, WormGPT, GhostGPT, FraudGPT. Estos sistemas, creados mediante jailbreaking de modelos éticos o modificación de modelos open-source, se comercializan en foros de dark web con modelos de suscripción y soporte técnico. Generan scripts maliciosos, exploits y campañas de ingeniería social sin restricciones éticas.
IA defensiva: detección comportamental y respuesta automatizada
Las organizaciones están respondiendo con IA defensiva igualmente sofisticada. El 51% de las empresas utilizan ahora IA o automatización en seguridad, y la adopción acelera rápidamente ante la evidencia de ROI demostrable.
Análisis comportamental y detección de anomalías. Los sistemas de User and Entity Behavior Analytics (UEBA) potenciados por IA establecen líneas base dinámicas de comportamiento normal para usuarios, dispositivos y aplicaciones, analizando miles de millones de eventos diarios. En lugar de buscar firmas conocidas, detectan desviaciones sutiles de patrones establecidos. Esta capacidad resulta crítica contra malware polimórfico y ataques zero-day: en entornos de alto riesgo, los sistemas basados en IA alcanzan tasas de detección de hasta el 98% frente a amenazas conocidas o que exhiben patrones anómalos reconocibles. Frente a ataques genuinamente inéditos —sin firma ni patrón comportamental previo— la detección basada en comportamiento reduce el riesgo pero no elimina la incertidumbre: la IA defensiva no reconoce la amenaza nueva, sino que detecta su desviación de la norma, lo que implica que ataques suficientemente cautelosos o bien diseñados para mimetizar comportamiento legítimo pueden eludir esa detección inicial.
Plataformas SIEM/XDR/SOAR con IA integrada. Las plataformas actuales de Security Information and Event Management (SIEM), Extended Detection and Response (XDR) y Security Orchestration, Automation and Response (SOAR) integran IA nativamente para correlacionar eventos entre sistemas dispares, reducir falsos positivos (hasta 95% de reducción en implementaciones maduras), y automatizar la respuesta. CrowdStrike reporta que su plataforma Falcon analiza 4,7 billones de eventos diarios con threat hunting 24/7 potenciado por IA. Microsoft Sentinel ha demostrado reducciones del 30% en tiempo medio de respuesta (MTTR) mediante correlación y análisis comportamental basados en IA.
Impacto económico demostrable. Según IBM, las organizaciones que utilizan IA y automatización extensivamente en seguridad reducen los costes medios de las brechas en $1,9 millones (más de 50% menos que organizaciones sin IA) y acortan los ciclos de contención en 80 días de media. Las organizaciones con plataformas AI-driven detectan amenazas un 60% más rápido y alcanzan un 95% de precisión en la detección.
Multiplicación de capacidades. La IA actúa como multiplicador de capacidades para equipos de seguridad: automatiza el triage de alertas (las organizaciones enfrentan un promedio de 4.500 alertas diarias ), ejecuta playbooks de respuesta automática para amenazas conocidas y permite que analistas junior operen a niveles de efectividad superiores. El 95% de profesionales de seguridad reporta que la IA mejora su velocidad y eficiencia para prevenir, detectar, responder y recuperarse de ataques.
La asimetría y el dilema estratégico
A pesar de capacidades defensivas avanzadas, persiste una asimetría preocupante: la mayoría de las compañías carece actualmente de madurez suficiente para contrarrestar amenazas avanzadas potenciadas por IA. El 78% de CISOs afirman que las amenazas impulsadas por IA tienen ahora «impacto significativo» en sus organizaciones.
La ciberseguridad se ha convertido en una batalla de IA contra IA, donde ambos lados operan a velocidades de máquina. Los atacantes automatizan el reconocimiento, generan exploits personalizados y adaptan sus tácticas en tiempo real. Los defensores correlacionan terabytes de telemetría, predicen vectores de ataque y ejecutan contención autónoma. El diferencial competitivo ya no reside en tener IA, sino en la sofisticación de los modelos, la calidad de los datos de entrenamiento, la velocidad de actualización de inteligencia de amenazas y la capacidad de integración entre superficies de ataque.
Securización de la IA: vulnerabilidades propias
Más allá de la batalla entre IA ofensiva y defensiva, emerge una tercera dimensión crítica: la securización de los propios sistemas de IA, que introducen vectores de ataque sin precedentes en el software tradicional. Los modelos de IA son vulnerables a ataques adversarios específicos: envenenamiento de datos de entrenamiento (data poisoning), donde atacantes inyectan datos maliciosos para degradar el modelo; evasión adversaria mediante perturbaciones imperceptibles que engañan al modelo durante la inferencia; y extracción de modelos vía consultas repetidas para robar propiedad intelectual.
Los LLMs añaden vectores adicionales documentados por OWASP: prompt injection (instrucciones maliciosas embebidas en inputs que alteran el comportamiento del modelo), insecure output handling (aplicaciones que confían ciegamente en outputs sin validación), training data poisoning, model denial of service y vulnerabilidades de supply chain. NIST publicó en 2024 guías específicas para desarrollo seguro de IA generativa, extendiendo su SSDF con controles diferenciados para cada fase del ciclo de vida. La securización efectiva requiere curación rigurosa de datasets, adversarial robustness testing, validación de inputs/outputs, sandboxing y red teaming específico de ML. Los equipos de seguridad deben incorporar expertise en ataques adversarios; los marcos de gobierno deben contemplar la IA como superficie de ataque independiente con controles propios.
El cibercrimen global alcanza billones anuales. Las organizaciones deben mantener una gobernanza robusta: los propios sistemas de IA defensivos son ahora objetivo de ataques (envenenamiento de modelos, prompt injection, evasión adversaria), creando una capa meta de riesgo que requiere protección especializada.
IA, privacidad y propiedad intelectual
Un conflicto estructural
La adopción masiva de IA generativa reabre debates fundamentales sobre privacidad y propiedad intelectual, enfrentando los modelos de negocio de sistemas que requieren datos masivos con marcos legales diseñados para minimización y control individual. Las tensiones no son meramente técnicas: reflejan choques estructurales entre la lógica operativa de LLMs y los principios que rigen protección de datos y derechos de autor.
Privacidad en LLMs: riesgos sistémicos en todo el ciclo de vida
En abril de 2025, el European Data Protection Board (EDPB) publicó un informe exhaustivo sobre riesgos de privacidad en LLMs, desarrollado bajo su programa Support Pool of Experts. El documento identifica que cada fase del ciclo de vida de un LLM introduce riesgos específicos de privacidad y protección de datos:
- Memorización involuntaria y fuga de datos personales. Los LLMs pueden memorizar fragmentos de datos personales presentes en datasets de entrenamiento y reproducirlos posteriormente en outputs generados. Este fenómeno no es un bug ocasional, sino un comportamiento intrínseco: el modelo almacena patrones estadísticos que incluyen datos sensibles. El EDPB documenta casos donde prompts específicos han logrado extraer información personal (nombres, emails, números de teléfono, datos médicos) que estaban en los datos de entrenamiento. La magnitud del problema escala con el tamaño del modelo y la sensibilidad de los datos procesados.
- Re-identificación y perfilado no intencional. Aunque los datos se anonimicen antes del entrenamiento, las técnicas de inferencia pueden re-identificar individuos combinando múltiples outputs del modelo. El EDPB advierte que los LLMs pueden generar perfiles detallados de individuos sin procesamiento explícito de datos personales identificables, lo que viola los principios GDPR de minimización y finalidad.
- Feedback loops sin salvaguardas. Las interacciones de usuarios con chatbots se almacenan frecuentemente para el fine-tuning posterior de los modelos, de modo que los datos sensibles revelados en conversaciones se incorporan al modelo sin consentimiento explícito ni garantías de eliminación posterior.
- Incompatibilidad estructural con GDPR. El informe de EDPB subraya tensiones irresolubles con los principios GDPR:
o Minimización de datos: los LLMs requieren datasets masivos, lo que contradice frontalmente la minimización.
o Derecho al olvido: no existen aún métodos robustos para «des-entrenar» modelos selectivamente (las técnicas emergentes como machine unlearning están en fase experimental).
o Transparencia: las arquitecturas transformer son black boxes donde rastrear el origen de outputs específicos es técnicamente complejo.
o Consentimiento: los datos scrapeados de internet raramente incluyen consentimiento para su uso en el entrenamiento de IA.
- Evaluación de impacto obligatoria. El EDPB concluye que, dada la naturaleza sistémica del procesamiento en LLMs, realizar Data Protection Impact Assessment (DPIA) según GDPR Art. 35 no es solo recomendable sino obligatorio en la mayoría de los casos, especialmente cuando los LLMs procesan datos sensibles o toman decisiones con impacto sobre individuos.
- Mitigaciones técnicas con coste. El reporte propone medidas como differential privacy (añadir ruido estadístico para impedir la identificación), federated learning (entrenar modelos sin centralizar datos), Retrieval-Augmented Generation (RAG, que separa el conocimiento actualizable de la memoria estática del LLM), y retrospective logging minimization (minimizar los datos en logs de sistema). Sin embargo, todas estas técnicas implican una reducción de la precisión, un coste computacional elevado o una funcionalidad reducida.
Propiedad intelectual: litigios masivos y colapso de infraestructura
La World Intellectual Property Organization (WIPO) ha dedicado múltiples sesiones de su «WIPO Conversation on IP and AI» a analizar el impacto de la IA generativa sobre el copyright. Las últimas sesiones se centraron específicamente en infraestructura para gestión de derechos, atribución y compensación en la era de la IA generativa.
Datos de entrenamiento: ¿uso legítimo o infracción masiva? El debate central no está resuelto. Las compañías de IA argumentan que entrenar modelos con contenido protegido constituye «fair use» (uso legítimo sin licencia), análogo a cómo los humanos aprenden leyendo. Los titulares de derechos argumentan que se trata de una copia no autorizada a escala industrial con intención comercial que crea sustitutos de mercado para el contenido original. Los litigios se multiplican; por citar algunos ejemplos:
- New York Times vs. OpenAI/Microsoft: el NYT demanda por el uso de millones de artículos sin consentimiento, argumentando que los modelos crean sustitutos de mercado que desvían tráfico de su paywall y que generan alucinaciones que dañan su reputación. Reclama miles de millones de dólares en daños.
- Getty Images vs. Stability AI: Getty acusa del uso sin consentimiento de más de 12 millones de fotografías para entrenar Stable Diffusion, incluyendo una infracción de la marca registrada (dado que el modelo replica la marca de agua de Getty).
- Artistas vs. Midjourney/Stability AI: los artistas argumentan que sus obras fueron scrapeadas sin permiso para entrenar modelos generadores de imágenes.
- Discográficas vs. Anthropic: Universal Music Group (UMG) y otras discográficas demandan por infracción masiva del uso de letras de canciones.
A diciembre de 2025, hay en curso más de 72 litigios de copyright activos contra compañías de IA. Hasta ahora, tres jueces han emitido decisiones preliminares sobre el uso legítimo: dos sentencias favorables a las compañías de IA, una contraria. No se esperan decisiones definitivas hasta el verano de 2026 como mínimo.
Titularidad de los outputs: un vacío legal. ¿Quién es el titular del contenido generado por IA? La mayoría de las jurisdicciones (incluyendo la US Copyright Office) mantiene que el copyright requiere autoría humana con «input creativo suficiente». El contenido generado puramente por IA sin intervención humana significativa cae en el dominio público. Pero los límites son difusos: ¿cuánta intervención humana (prompt engineering, selección, post-edición) es «suficiente»?
Colapso de la infraestructura de copyright. La WIPO advierte de que los sistemas de gestión colectiva de derechos, diseñados para volúmenes manejables de obras humanas, colapsan ante los billones de outputs generados por IA diariamente. No existen infraestructuras escalables para el seguimiento, la atribución y la compensación. Las últimas sesiones de la WIPO exploraron la necesidad de nuevas infraestructuras técnicas y marcos regulatorios, pero las soluciones prácticas permanecen especulativas.
Fragmentación y ausencia de consenso global
La fragmentación regulatoria amplifica la incertidumbre. La UE exige transparencia sobre los datos de entrenamiento (AI Act Art. 53), Estados Unidos carece de legislación federal específica, China impone un control estatal estricto sobre datos y algoritmos. Las compañías que operan globalmente enfrentan requisitos no armonizados. Las tecnologías de preservación de la privacidad (differential privacy, federated learning, homomorphic encryption) ofrecen rutas técnicas para reconciliar la privacidad con la utilidad de la IA, pero están lejos de la adopción masiva: son costosas, complejas y reducen el rendimiento. La tensión entre la innovación tecnológica acelerada y los marcos legales diseñados para paradigmas anteriores permanece, por ahora, irresuelta.
Índice de la publicación

Introducción

Resumen ejecutivo

La explosión tecnológica de la IA


Gobierno de la IA e impacto en personas

Fronteras de la IA

Caso práctico: GenMS™ Sybil

Conclusión

Referencias y glosario